
webAI: AI on the Edge
Overview
AI has exploded, and if software was eating the world, AI is swallowing software. The assumption has been that AI requires cloud, with vast amounts of Nvidia GPUs. While that is true to build general purpose LLMs, what if those LLMs became smaller built-for-purpose (SLMs), and what if we could leverage AI using edge devices, such as laptops, phones or tablets? What if we could bring AI closer to the human?
Advantages of Edge AI
Edge AI is exactly that, using general-purpose off-the-shelf hardware, and focusing on specialist or domain-specific SLMs. After all, if I am trying to understand a defect of an airplane part, in the field, I probably don’t need the AI to also know about sports trivia, right?
Where cloud excels at building general-purpose LLMs that are pretty good at everything, it struggles with making it exceptionally good at something very specific and this is where I think Edge AI can really excel. Below are some of the advantages of Edge AI:
- Cost Efficiency / Increased ROI
- Enhanced Data Privacy
- Real-time data processing
- Reduced network congestion
Introducing webAI
As I discovered recently, there is a company focusing on Edge AI, webAI. Their approach is to focus on edge devices, laptops, phones, tablets, and bring AI to these devices, without the need to connect to the cloud. WebAI has focused on Apple silicon, and that bet has paid off with recent advancements in the M4 chip, enabling AI, without the complexity of running complex infrastructure, requiring cloud.
WebAI provides a platform for training, inference, and building AI apps, that all run on consumer-grade Apple hardware: phones, tablets, or laptops. WebAI provides a platform with several components: Navigator, Companion, and webAI CLI.
Navigator
Navigator provides a drag-and-drop interface, connecting inputs such as cameras, OCR (Optical Character Recognition), OD (Object Detection), allowing users to train AI models and ultimately build specialist AI assistants that are domain specific.
Building an OD application on AI becomes as simple as clicking together a few boxes using navigator.
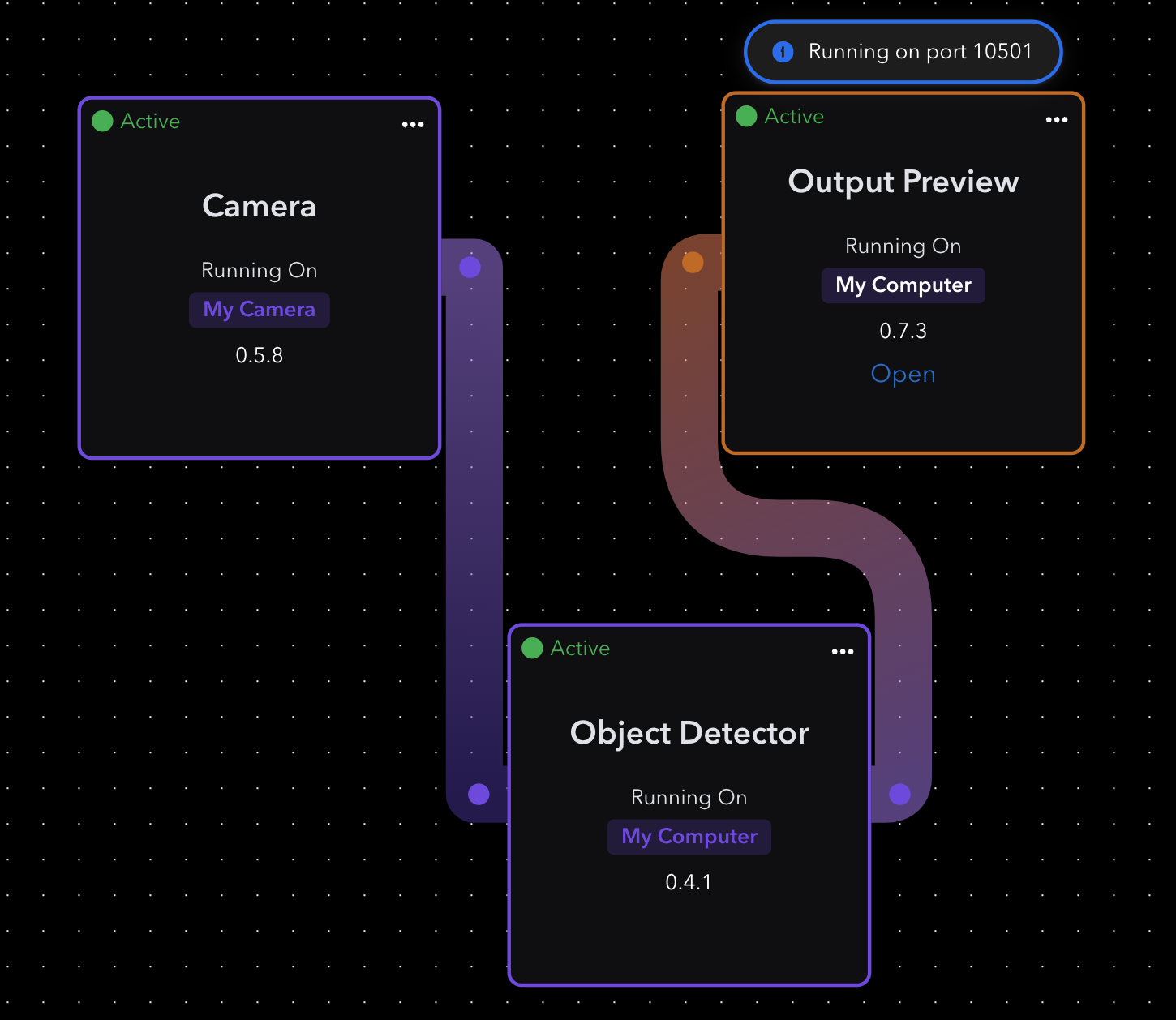
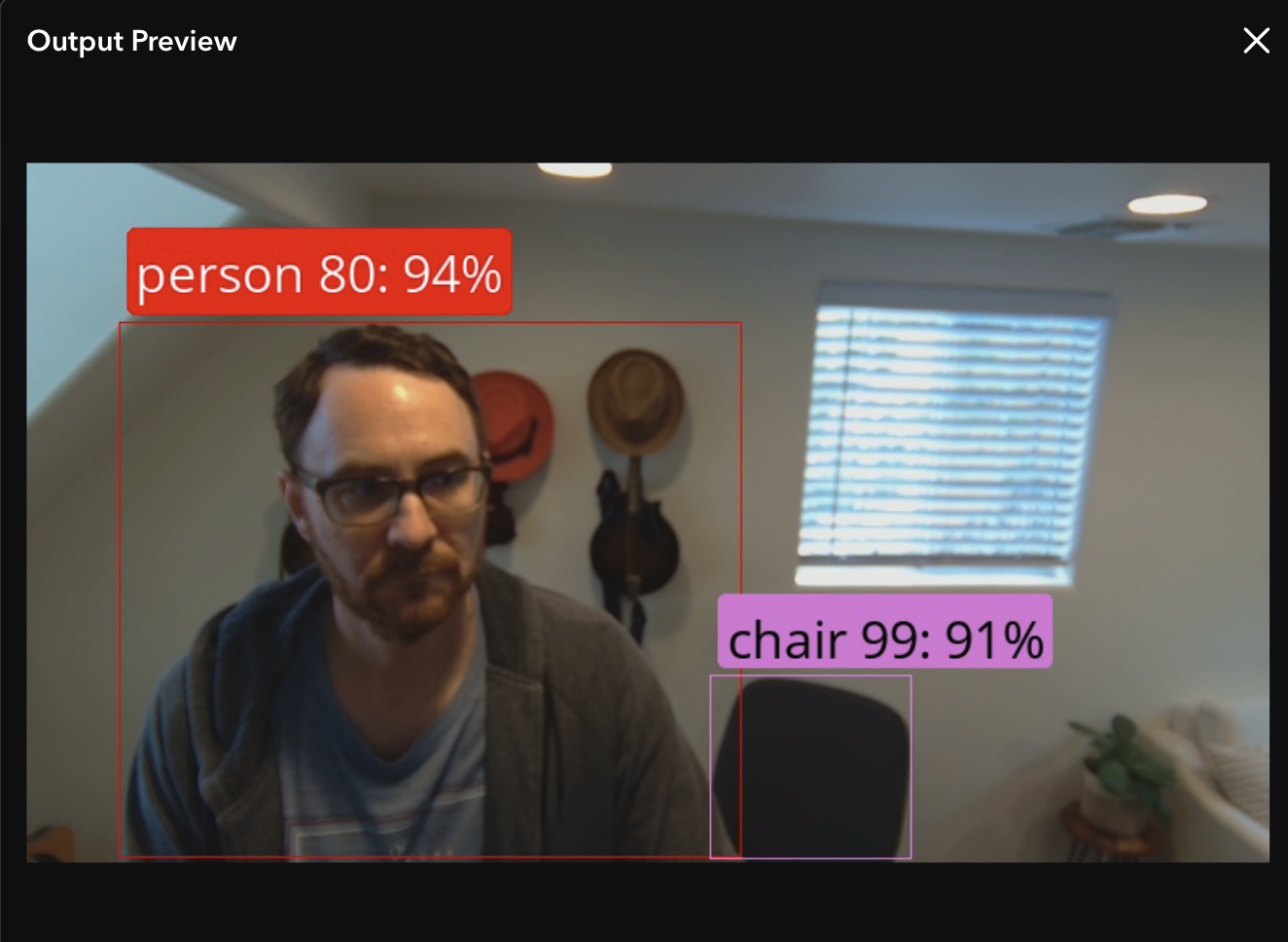
Clicking open under output preview shows results.
Elements
Elements are the building blocks of Navigator. An element is a packaging of code, meant to represent a specific function. There are many built-in elements, but one can also create custom elements as well, for virtually anything.
Flow
A flow is simple a workflow or sequence of elements to perform a trained function and produce an output. Usually it would represent an input, inference element and an output but many different flows can be imagined.
Clusters
Clusters are groups of devices on your network running the webAI CLI (worker). These can be any device, as long as it is running on Apple silicon. Clusters allows for pooling together resources for a common purpose.
Deployments
A deployment assigns a flow to a cluster or group of devices, so that it is decoupled from running in Navigator, on your local machine. Development or prototyping is done inside navigator and then deployed to a cluster or set of device(s) when ready for further testing and eventually production.
Companion
Companion allows you to connect to your deployments, running on a cluster, and interface through an AI assistant chat.
CLI
The webAI cli is used to run the worker. This is a lightweight process that allows a device to connect to the webAI platform and ultimately receive deployments.
AI Assistant Example
Lets put everything together, in a real-world use case, and build a specialized assistant, that will be able to answer very domain specific questions, that a generalized LLM may struggle with.
First, I want to make my general-purpose LLM more accurate, providing detailed documentation that will be used in inference. First, a RAG Inference Pipeline will be built in Navigator to generate vector indexing so detailed and specific documentation can be used by the LLM.
Rag Inference Pipeline
To build the RAG inference pipeline, we will need to use four elements from Navigator: OCR, Chunking, Embedding and Vector Indexing.
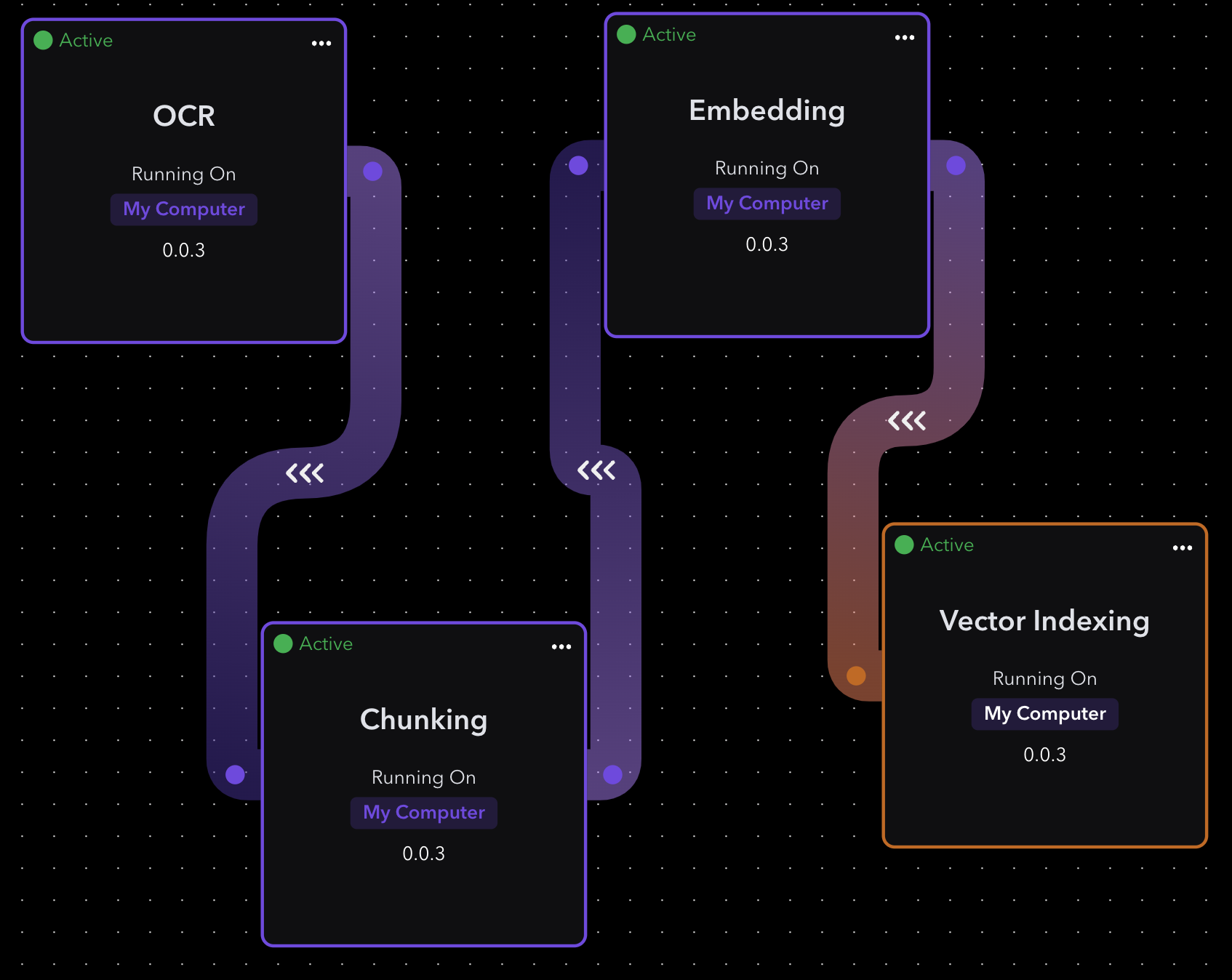
OCR Element
The OCR element allows for reading our text documents, we can go into settings and define the directory where all the documents we want exist. Here we configured our docs folder.
Chunking Element
The Chunking element lets us break up the text into smaller pieces, for efficient downstream processing. We didn’t change any defaults.
Embedding Element
The embedding element creates a mathematical representation of the text, for storing in a vector index. We didn’t change any of the defaults.
Vector Indexing Element
The Vector Indexing element writes the index into a vector database. Here we simply specified the folder path for writing the vector index. Each run will generate a new folder with that runs vector database.
LLM Chat Assistant
Now that we have vector representation of our text data, we can build our AI assistant. To do this we will need to use the following elements from Navigator: API, Embedding, Vector Retrieval, Prompt Templating and LLM Chat.
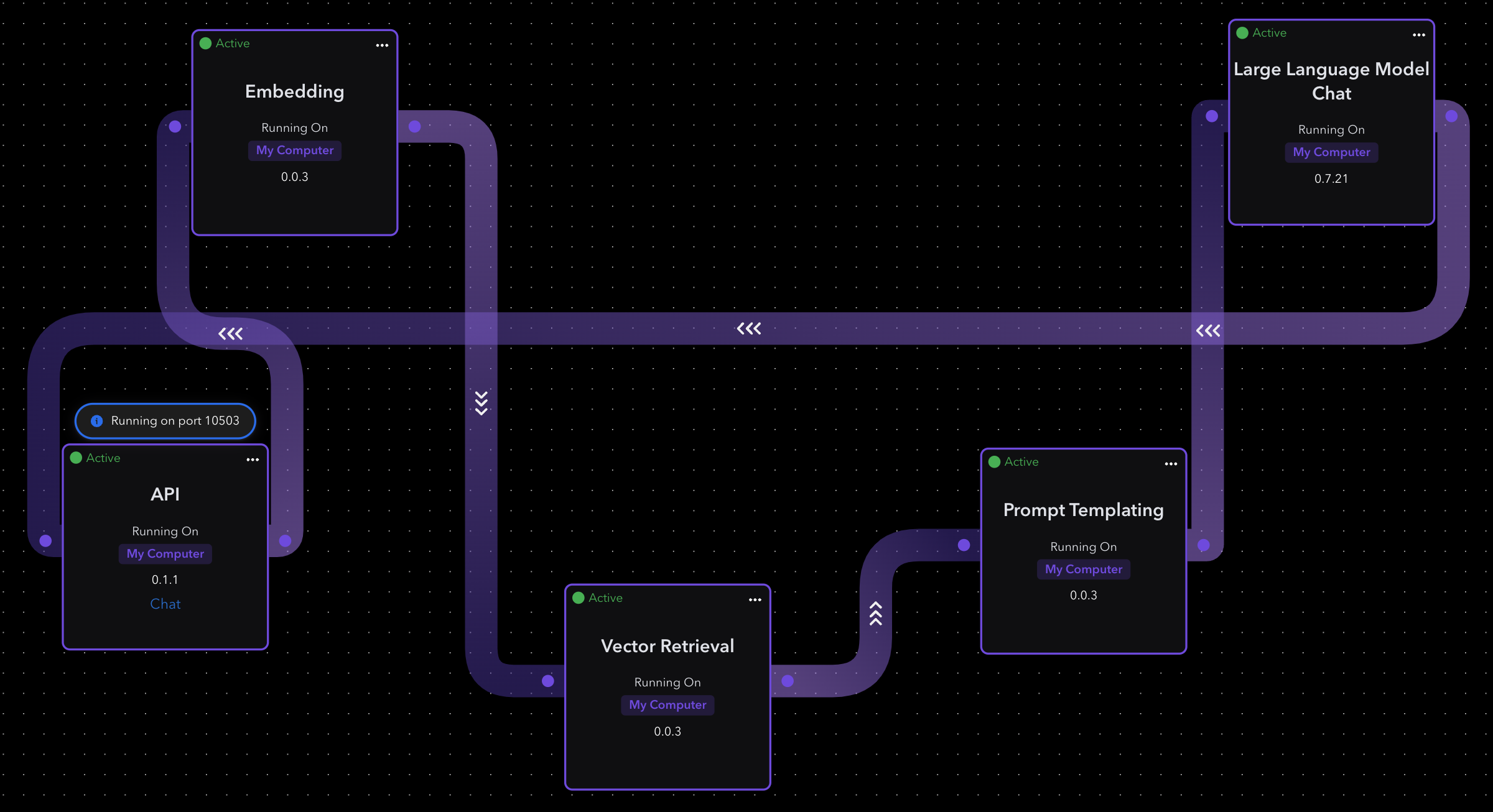
API Element
The API elements communicates with LLM and the user. It takes user input and sends a prompt back to the user. We didn’t change and defaults.
Embedding Element
The Embedding element as mentioned earlier, creates mathematical representation of the data, in this case, the user input. We didn’t change any defaults.
Vector Retrieval Element
The Vector Retrieval gets result from vector database. Here we simply provided the folder to where our vector database was created, with the RAG Inference Pipeline.
Prompt Templating Element
The Prompt Templating puts our retrieved contexts into the prompt template. We didn’t change any defaults.
LLM Chat Element
The LLM Chat element displays a chat interface, allowing user to interact with the pre-configured LLM. You can choose many different types of LLMs. Llama is the default LLM. We didn’t change any defaults.
Observations
Using Navigator, we can open a chat interface, and start using our specialized assistant. In this case, we uploaded several documents to RAG pipeline. Those documents go into detail about how to setup observability for a Temporal worker. Below I asked a very specific question about observability of a Temporal worker.
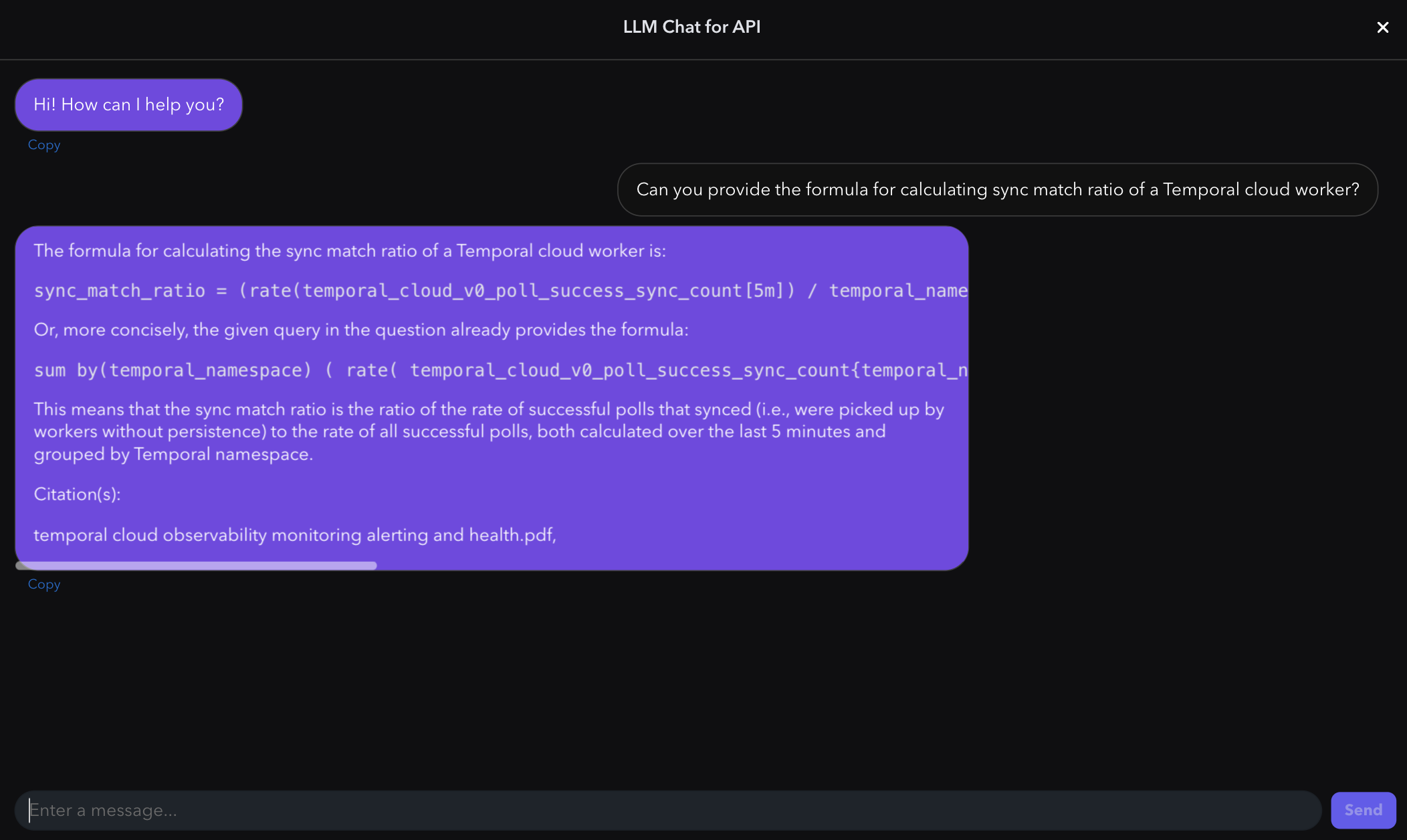
As we can see the AI returned a response to our question which was correct, but also cited one of the documents that were part of our RAG Inference Pipeline, as its source of truth.
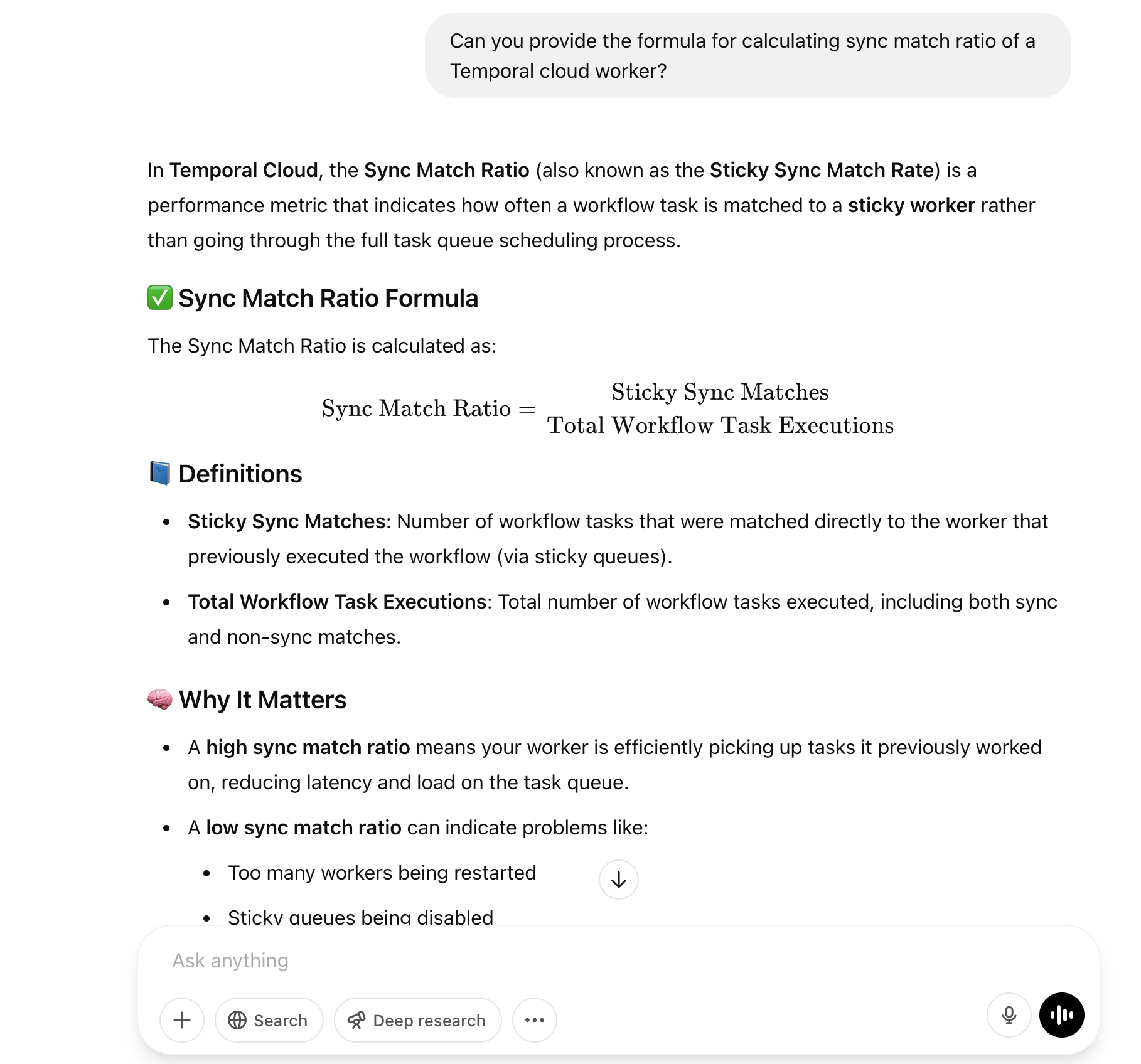
Now lets compare the same question with ChatGPT 4o. The answer seems very convincing, but it is in fact wrong and a hallucination.
Summary
Edge AI is a very quickly emerging space in the AI ecosystem. WebAI is at the forefront, enabling not only new use-cases, but democratizing the way we build and ship AI capabilities with its Navigator platform, bringing AI to the edge, using off-the-shelf consumer-grade hardware instead of incredibly expensive cloud-based GPUs. This should greatly increase the speed and impact we get from AI in our daily lives, bringing AI closer, where it can have the most impact. I am incredibly excited to see where Edge AI goes next!
(c) 2025 Keith Tenzer