
Disaster Recovery with Containers? You Bet!

Overview
In this article we will discuss the benefits containers bring to business continuance, reveal concepts for applying containers to disaster recovery and of course show disaster recovery of a live database between production and DR OpenShift environments. Business continuance of course is all about maintaining critical business functions, during and after a disaster has occurred. Business continuance defines two main criteria: recovery point objective (RPO) and recovery time objective (RTO). RPO amounts to how much data loss is tolerable and RTO how quickly services can be restored when a disaster occurs. Disaster recovery outlines the processes as well as technology for how an organization responds to a disaster. Disaster recovery can be viewed as the implementation of RPO and RTO. Most organizations today have DR capabilities but there many challenges.
- Cost - DR usually is at least doubles the price.
- Efficiency - DR requires regular testing and in the event of a disaster, resources must be available. This leads to idle resources for 99.9% of the time.
- Complexity - Updating applications is complex enough but DR requires a complete redeployment where the DR side almost never mirrors production due to cost.
- Outdated - Business continuance only deals with one aspect, disaster recovery but as mentioned cloud-native applications are active/active so to be effective today, business continuance architectures must cover DR and multi-site.
- Slow - DR often is not 100% automated and recovery is often dependent on manual procedures that may not be up to date or even tested with the latest application deployment.
I would take these challenges even further and suggest that for many organizations business continuance and DR is nothing more than a false safety net. It costs a fortune and in the event of a true disaster probably won't be able to deliver RPO and RTO for all critical applications. How could it when DR is not part of the continuous deployment pipeline and being tested with each application update? How could it with the level of complexity and scale that exists today and not 100% automation?
A New Approach
It is well overdue that organizations refresh and re-think their disaster recovery strategies. The good news is business continuance forced most companies into a two-site architecture, even if it were just focused on DR, the infrastructure is already there. In addition with the emergence of public cloud we have a plethora of infrastructure options.
Re-thinking business continuance
- DR & Multi-site - Business continuance plans should focus on a true multi-site architecture where applications have choice, can go with active/passive traditional or active/active cloud-native approaches across regions or availability zones.
- Regions - Move away from limiting terminology such as production or DR. Each site should be a region such as Europe East or West. It should be just as easy to span applications across regions or configure a region for DR from the application perspective.
- Platform - It goes without saying you will want software-defined networking and storage. Most organizations will want to augment their private with public clouds. On the private cloud infrastructure side, if you aren't already doing OpenStack you really ought to be going down that path.
- Technology - All applications should be containerized. Containers allow for packaging the application with all dependencies and running it across any infrastructure. Containers are not just a DevOps technology, they are essential to multi-cloud. The application deployment configuration is implicit, allowing for 100% automated, fast, reproducible deployments. In addition containers allow DR to be treated as just another stage in the CI/CD pipeline.
Obviously containers is a no-brainer for cloud-native applications but anything can be containerized and there are many advantages of containerization for non cloud-native applications. Disaster recovery is just one example.
Using OpenStack allows us to move our already existing private cloud infrastructure to a multi-site, region and cloud approach. It allows organizations to mirror their public cloud environments so that end users don't even notice difference between organizationally defined regions, US West (OpenStack) and US East (AWS us-east-1) regions.
Containers also need a platform that provides orchestration, security, routing, storage and integration with underlying infrastructure platform. Kubernetes is obviously the industry standard for how to orchestrate containers but by itself isn't enough. OpenShift is the platform running on Kubernetes that can provide a true runtime for containerized applications across Google, Azure, AWS, OpenStack or whatever other infrastructure may exist.
Advantages of a new approach
- Reduce Cost - The DR site is no longer a single purpose site. It has been transformed into a region. Test or DR workloads could share infrastructure. This means 99.9% of the time, when we aren't in disaster mode, resource utilization remains high as test would be using those resources.
- Reduce RTO - Usually measured in hours, days or weeks. Again, RTO is how quickly it takes to get up and running after disaster. Using containers allows us to start applications in seconds and do so in 100% automated fashion. As such we can also greatly reduce RTO. The cost alone of restoring service several hours faster in event of disaster could alone pay for DR infrastructure for some organizations.
- Ensure DR Actually Works - The only way to ensure something will work is to test it. Using containers allows DR to be just another stage in CI/CD pipeline ensuring every application change is tested from DR perspective.
- Support Cloud Native - Expanding DR architecture from single to multi purpose enables the same infrastructure, already in place, to handle cloud native workloads as well. This of course, further increases the efficiency and drives down cost.
Getting Started
Since most organizations already have DR capabilities, the key question is how to get started and moving in the right direction with the least amount of cost as well as effort.
Here are some additional ideas to get started.
- Don't rip and replace - Initially I would keep existing DR and design new approach that could either use existing infrastructure or new infrastructure (maybe public cloud). The idea is to introduce a new DR service that is better and at lower cost. If you achieve that, applications will be lining up to migrate and this is how you can expand container adoption at the same time.
- Start with multisite first architecture - Define your regions, workloads, production, dev, test and DR. Then decide where workloads should run. Ideally each region should be capable of running all workloads but that may not be possible.
- Understand resource usage - One of the main goals should be to increase utilization of existing infrastructure. Understand where current utilization lies and how to increase it. If your paying for resources all the time you better use them!
- Embrace public cloud - DR is an absolute perfect use case for a pay-per-use model. DR is only used when testing or in event of disaster. Not having to pay up front for required scale is a very hard offer to turn down. At a minimum ,I would provide capability to use public cloud as DR region. If business can run their DR in public cloud then it should be an option.
- Define Cost Models - Having your own DR infrastructure vs pay-per-use usually means paying up front vs deferred. Most organizations don't have the scale to really make pay-per-use work.
Understanding applications and their requirements are key. In most organizations you will have the following profiles.
- Single site application (traditional) - runs on a single site has no disaster recovery.
- Multi site application (cloud-native) - spread evenly across multiple sites. Disaster recovery is built-in and is simply a matter of re-scaling. Usually three sites works better than two.
- DR application (traditional) - runs primarily on single site and can failover in the event of a disaster to a secondary site.
We should get to the point where a application owner simply selects one of these three profile and the application is setup accordingly, including CI/CD.
Making DR Effective and Efficient
Single site and multi site applications are pretty easy to deal with from infrastructure perspective but DR is not, let alone making it somehow efficient. As such we need to think out-of-the-box to really drive needed improvements. As discussed, one of the main issues with DR is the resources need to be available but otherwise are not used. Sure as mentioned above public cloud solves that easily but what if you have workloads that can't use public cloud or simply aren't there yet?
One idea here is to force the test and development environments to run in the region assigned for an applications DR. Under normal operations infrastructure at DR region is used for test, development and DR testing. In the event of a disaster development and test environments are scaled down and DR is scaled up. Using containers and a platform like OpenShift we can easily achieve this. In addition a global load balancer (or active/active ingress router) is needed to balance traffic between region running production and DR. A DR cut-over is simply an Blue/Green deployment, a matter of redirecting the URL. Such an architecture not only makes DR testing simple but ensures DR resources are in use, all the time. In the event that production is larger than all of development and test, additional resources may need to be available. Fortunately most test environments are larger than production.
The diagram below illustrates how a CI/CD concept using containers and OpenShift as a platform could work. OpenShift projects are split between Dev, Test, DR and production. The Dev, Test and DR environments run on one OpenShift cluster and Production another. Each application change goes through CI/CD pipeline where the change is tested in Dev, Test and DR before going to production. In the event of a disaster we simply scale Test and Dev to zero and scale-up DR.
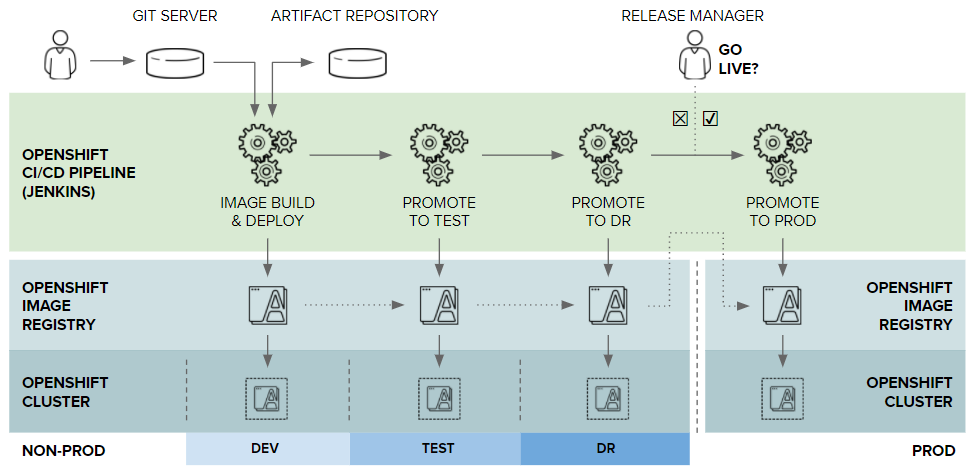
Image Source: Red Hat
Storage and Replication
When considering DR for OpenShift/Kubernetes there are several layers that require replication. In OpenShift/Kubernetes there is the project/namespace level, the images and any persistent volumes.
Projects
Objects such as deployment configs, secrets or even build configs can easily be exported and imported. Everything in OpenShift/Kubernetes is an object and as such can easily be exported and imported via yaml or json. Some scripts to do exactly that are already being developed but can also be easily written. One of the key things to remember is that the SElinux groups, uids and ranges must be exactly the same between the production and DR project otherwise access to a persistent volume will be forbidden by SELinux.
Images
Since applications themselves are packaged nicely into containers, each application update results in a new image. The best way to distribute images to DR projects is to add DR to the CI/CD pipeline. Images would be pushed between OpenShift clusters using CI/CD pipeline. The above diagram illustrates this concept and how images can be promoted across the lifecycle stages.
Persistent Volumes
Containers themselves are immutable but can (in case of OpenShift/Kubernetes) mount Persistent Volumes (PVs) by making a Persistent Volume Claim (PVC). A PVC binds a PV to a particular pod where a single or multiple containers are running. A PV is a mapping to a physical disk or file system (in the case of file based storage such as NFS). If a pod is going to move nodes, storage must be unmapped, remapped and mounted on the new node before it can be made available to the pods and eventually containers. Thankfully this is all done automatically by OpenShift assuming the storage has a dynamic provisioner. Today OpenStack, Ceph, Gluster, Azure, Google and AWS all have dynamic provsioners that are shipped and supported in OpenShift. You will want to choose one of these which brings me back to OpenStack for on-premise. OpenStack in turn supports many other storage systems so the clear advantage here is the abstraction layer of the IaaS.
Replication itself of persistent volumes will be done either synchronous or asynchronously, depending on latency. Most DR scenarios today rely on asynchronous replication which is why recovery point objective (RPO) is typically measured in hours or days. In case of OpenStack if your production and DR sites are close (within 100km) you may choose to stretch OpenStack across sites. Three sites instead of two would be more ideal due to quorum but both could work. Another option at IaaS layer is separate OpenStack environments and then rely on underlying storage replication to ensure your persistent volumes are asynchronously replicated between sites or environments.
A Proof of Concept
As already alluded, multiple OpenShift clusters are needed. In the proof of concept I have created two OpenShift clusters Europe West and Europe East. Both are tenants in a single OpenStack environment.
The diagram below illustrates the architecture. In this case since we are talking about a single OpenStack environment, cinder storage is being provided across the cluster.
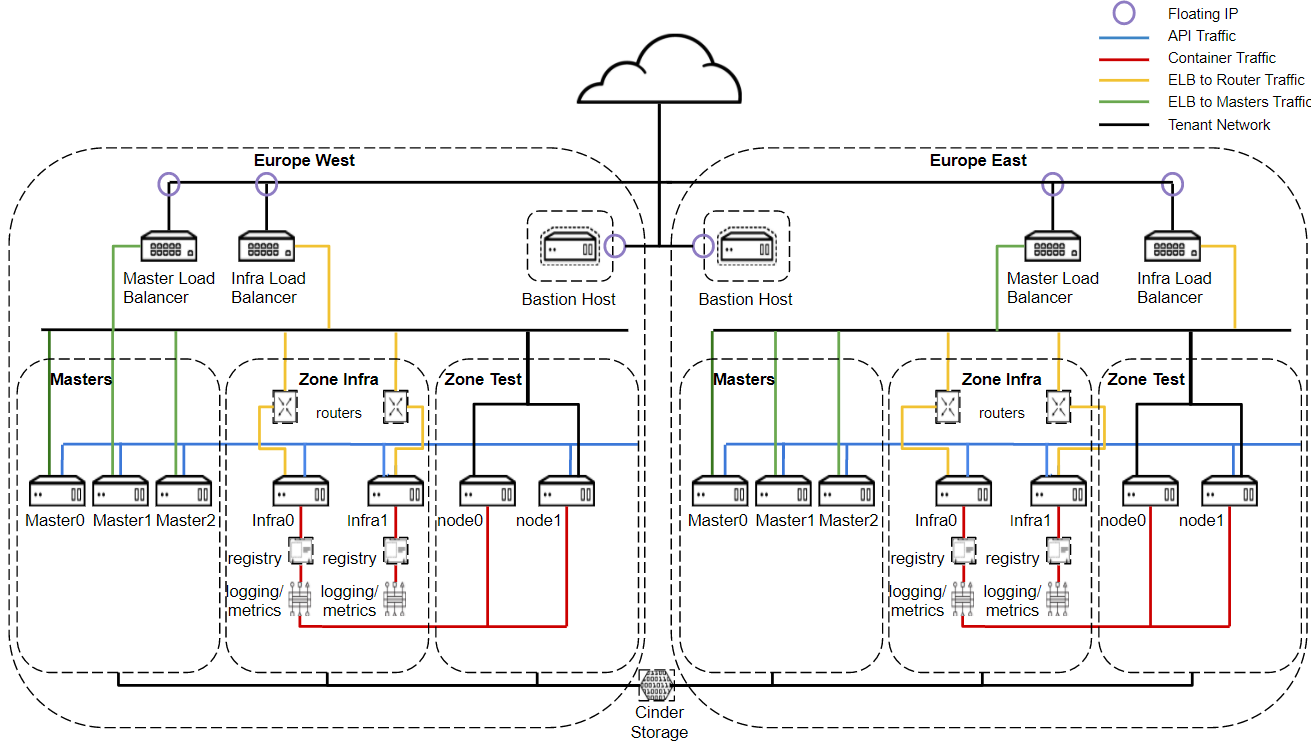
In this example I will show how to DR a live mariadb database running in container on OpenShift from Europe West to Europe East.
[Production OpenShift]
- Export secrets persistent volume, persistent volume claim and deployment config.
- Export project itself.
- Scale production to 0 (this of course simulates a site failure).
[OpenStack Europe West]
- Determine persistent volume mapping and identify cinder volume UUID in OpenStack.
- Using volume UUID start a transfer request of the volume. Moving storage between tenants in OpenStack is done via transfer, of course storage volumes must be visible to all nodes.
[OpenStack Europe East]
- Using the transfer id and auth_key, issue a transfer accept to import the volume from europe west.
[DR OpenShift]
- Create DR project (if not done so already) using the exact same SELinux Groups, UIDs and Ranges as production project.
- Import secrets from previous export into DR project.
- Import persistent volume (PV) from previous export.
- Import persistent volume claim (PVC) into DR project from previous export.
- Import deployment config into DR project from previous export.
- Start database. The OpenShift node will be scheduled, Cinder volume automatically mapped/mounted and the database will start.
Just like magic!
These of course are the different steps across both Paas and IaaS layers. Ideally you would create the DR project at time when production project is created and use CI/CD to keep things in sync. Then assuming storage is replicated you should be able to just scale replica in deployment and things will start. As mentioned for applications which are image and config dependent you would use CI/CD tooling.
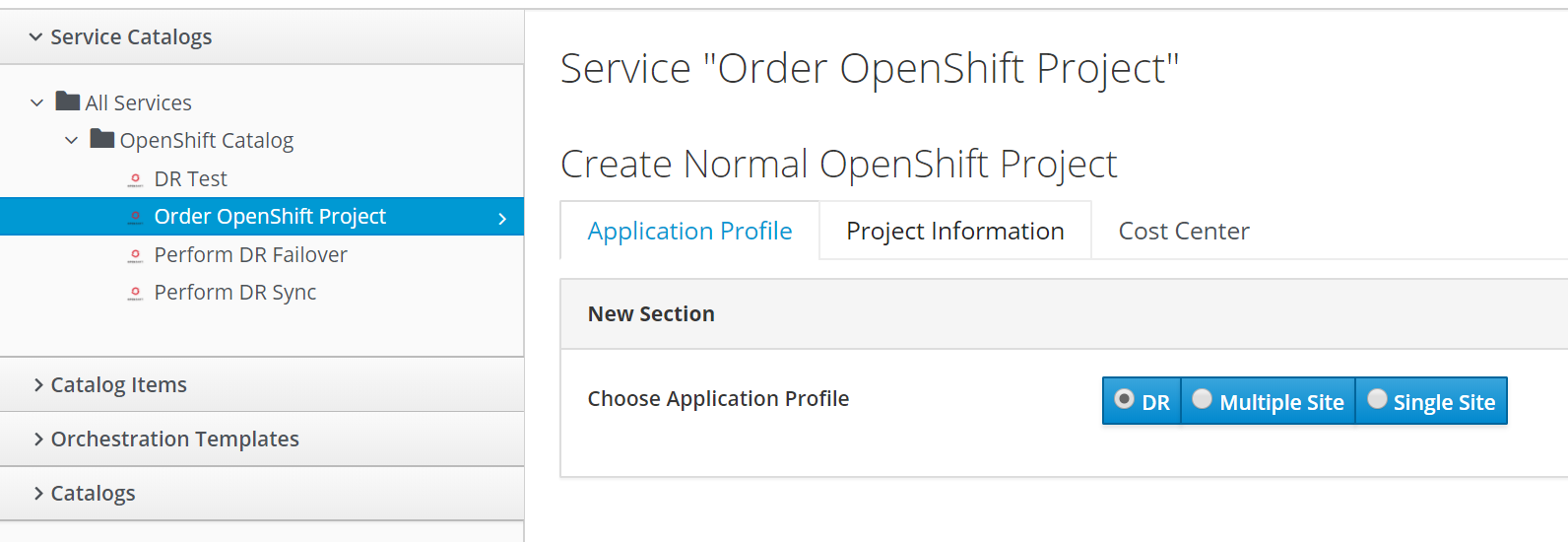
CloudForms or CI/CD could be used to easily create the appropriate environments according to user inputs. BTW did I mention CloudForms is included in OpenShift? Here is an example of what you could build with CloudForms to provide an application environment as-a-service for the various application profiles.
Application Profile Choice
Project Details
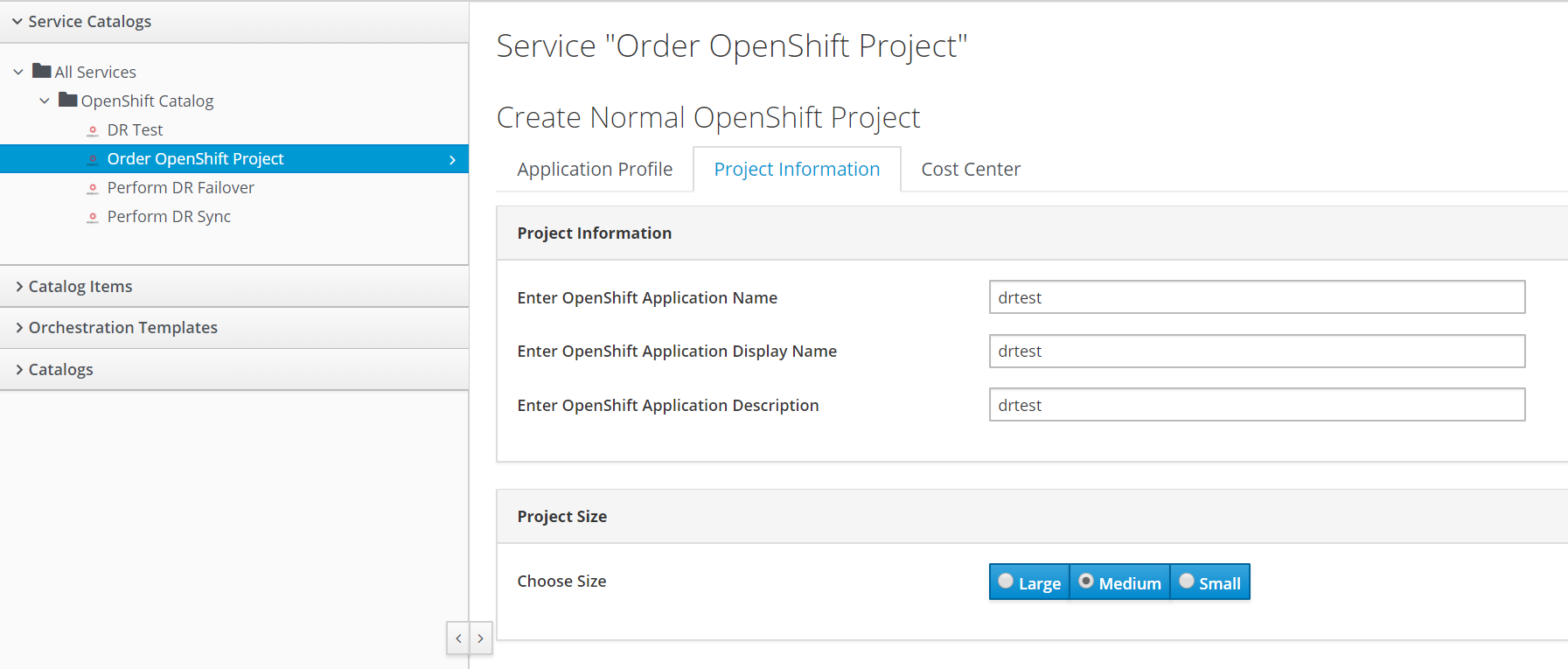
Cost Center and Justification
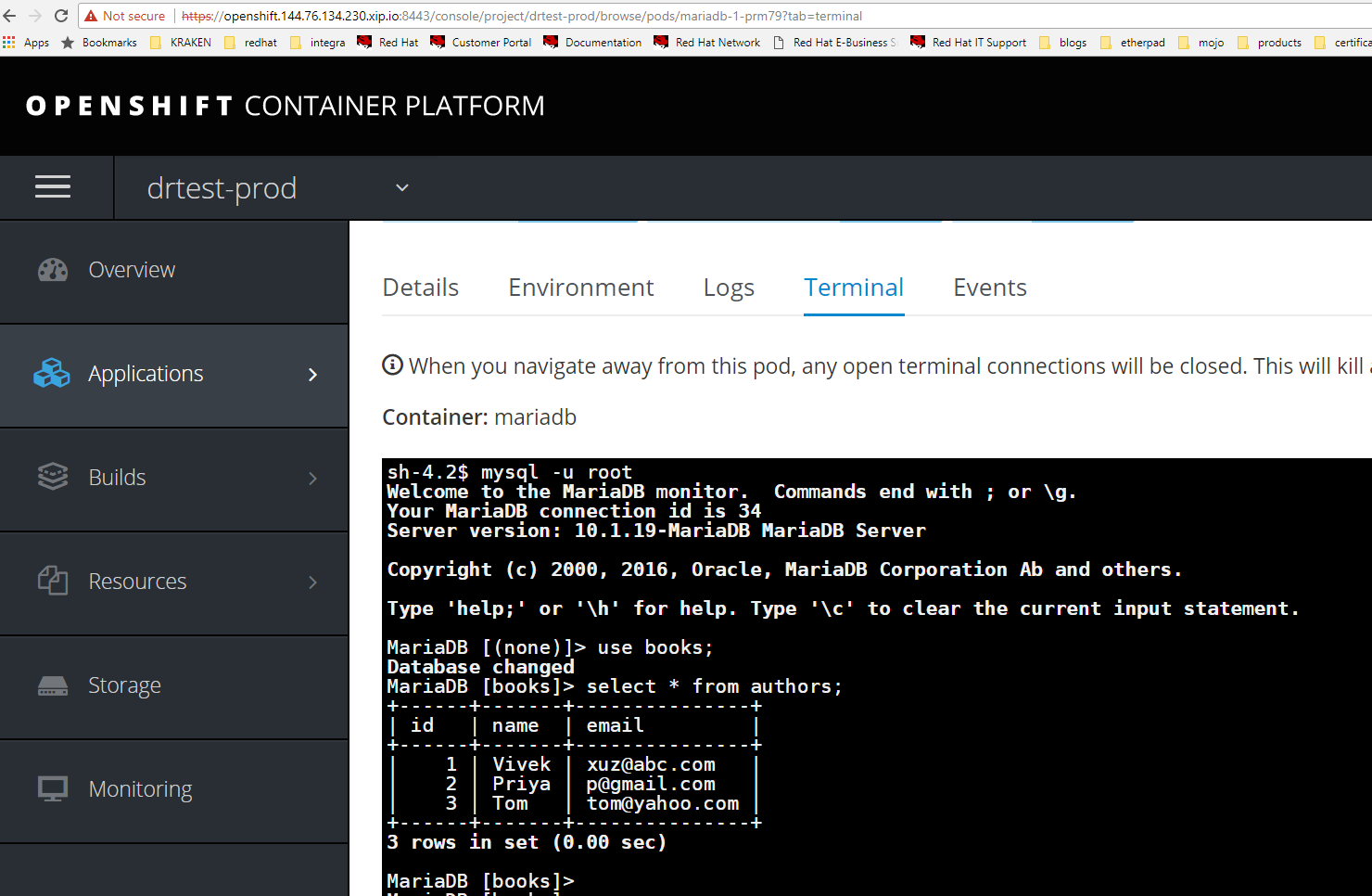
Now we will go through a DR scenario.
Verify database on production site running in project drtest-prod.
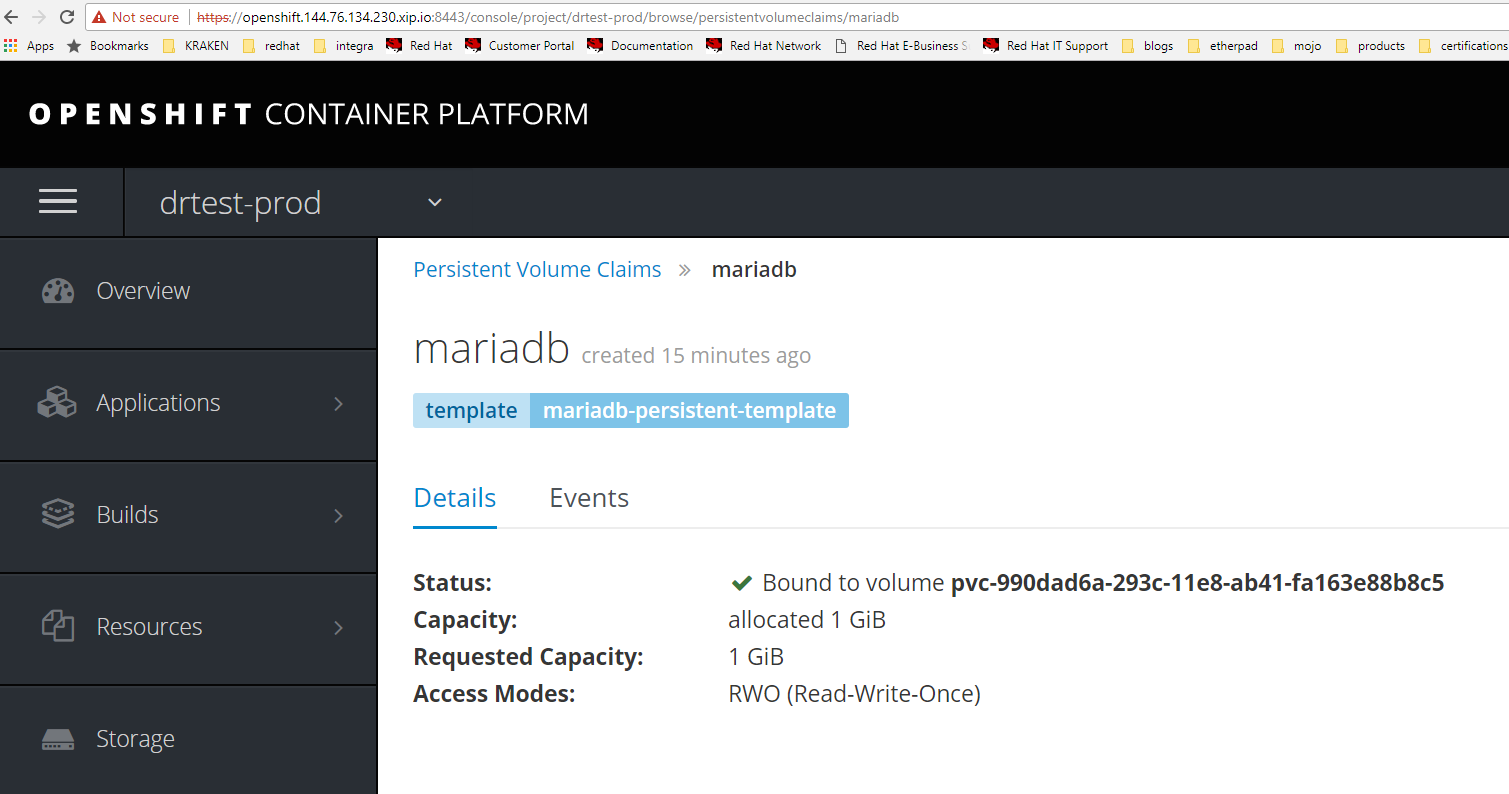
Verify persistent volume on production site runngin in project drtest-prod.
Execute Script to perform DR failover.
The script is available here in Github.
The script takes six arguments.
- Project name.
- Deployment config.
- Endpoint for OpenShift production cluster.
- Token for OpenShift production cluster.
- Endpoint for OpenShift DR cluster.
- Token for OpenShift production cluster.
[cloud-user@bastion ~]$ ./perform-dr-failover.sh drtest mariadb \n https://openshift.144.76.134.230.xip.io:8443 PqIeLvATB4liHqLpd018yd2kppUt-4OiXX6BLMAjBSo \n https://openshift.144.76.134.229.xip.io:8443 nQEbP4MD_6kY6k2YkRenljtKDWrvCT9Cy-uhb-YiNnY
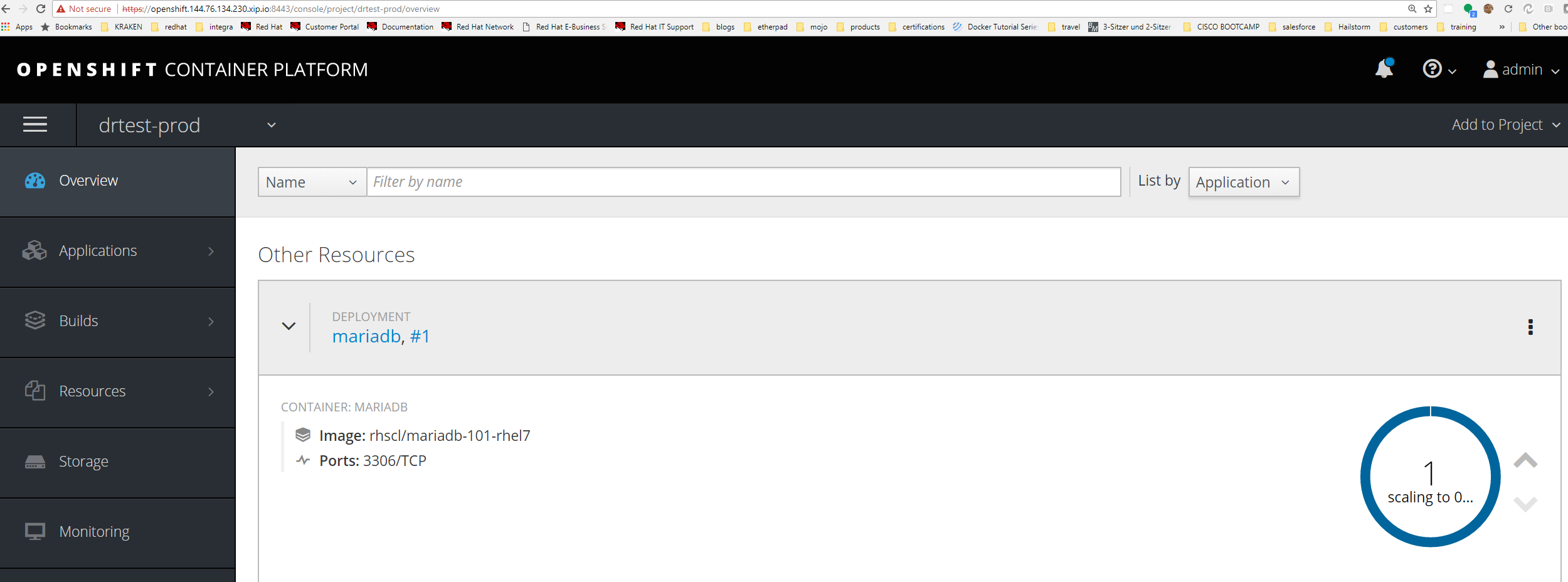
Production is scaled down.
Volume transfer request generated in Europe West OpenStack tenant.
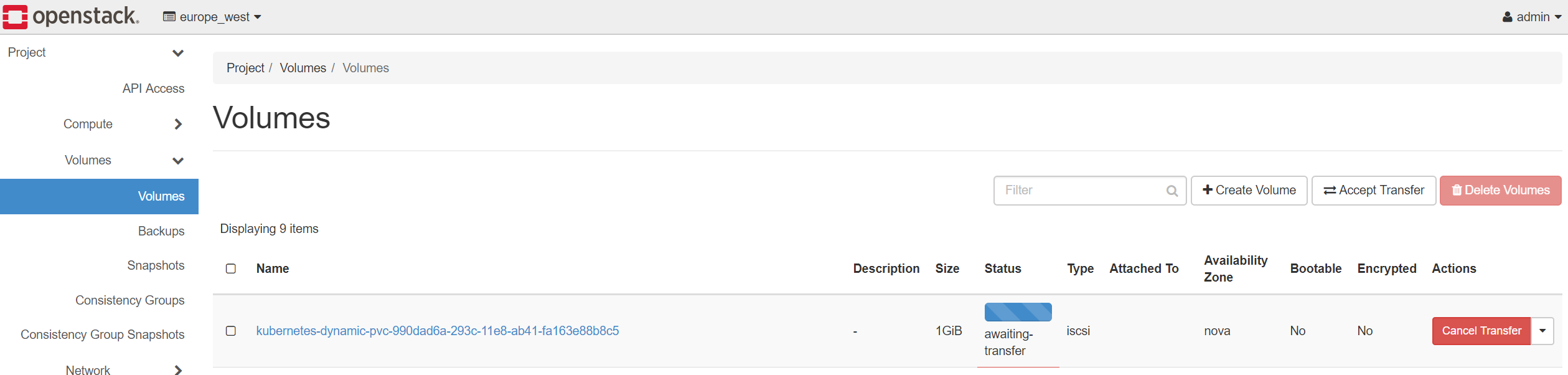
Volume transfer request is accepted in Europe East OpenStack tenant.
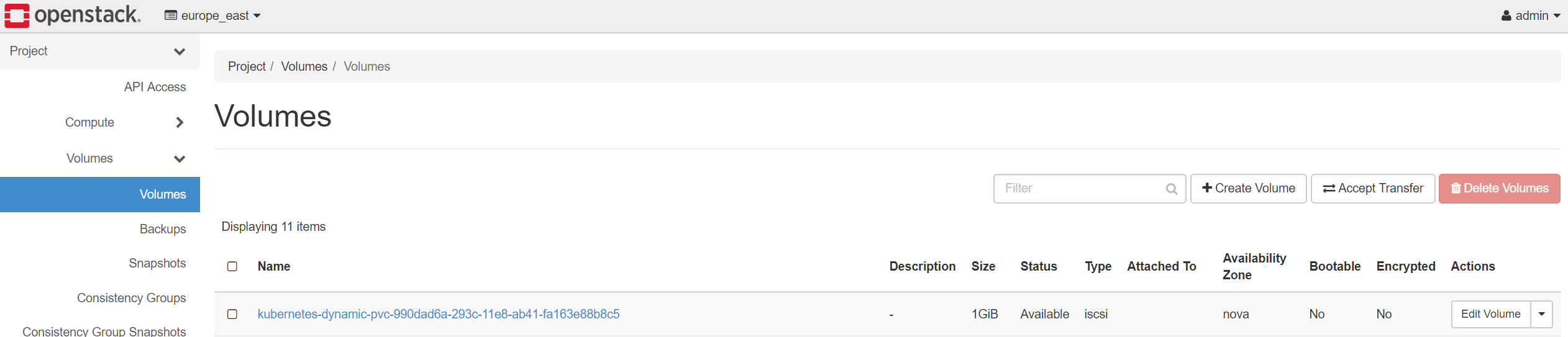
Verify persistent volume on DR site running in project drtest-dr.
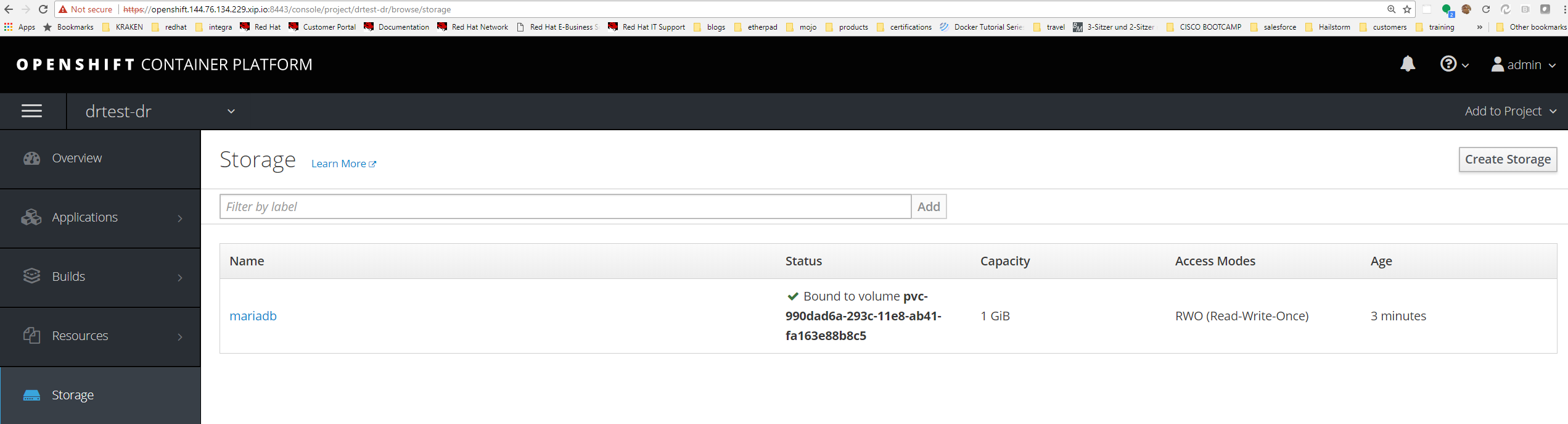
Deploy mariadb in europe west.
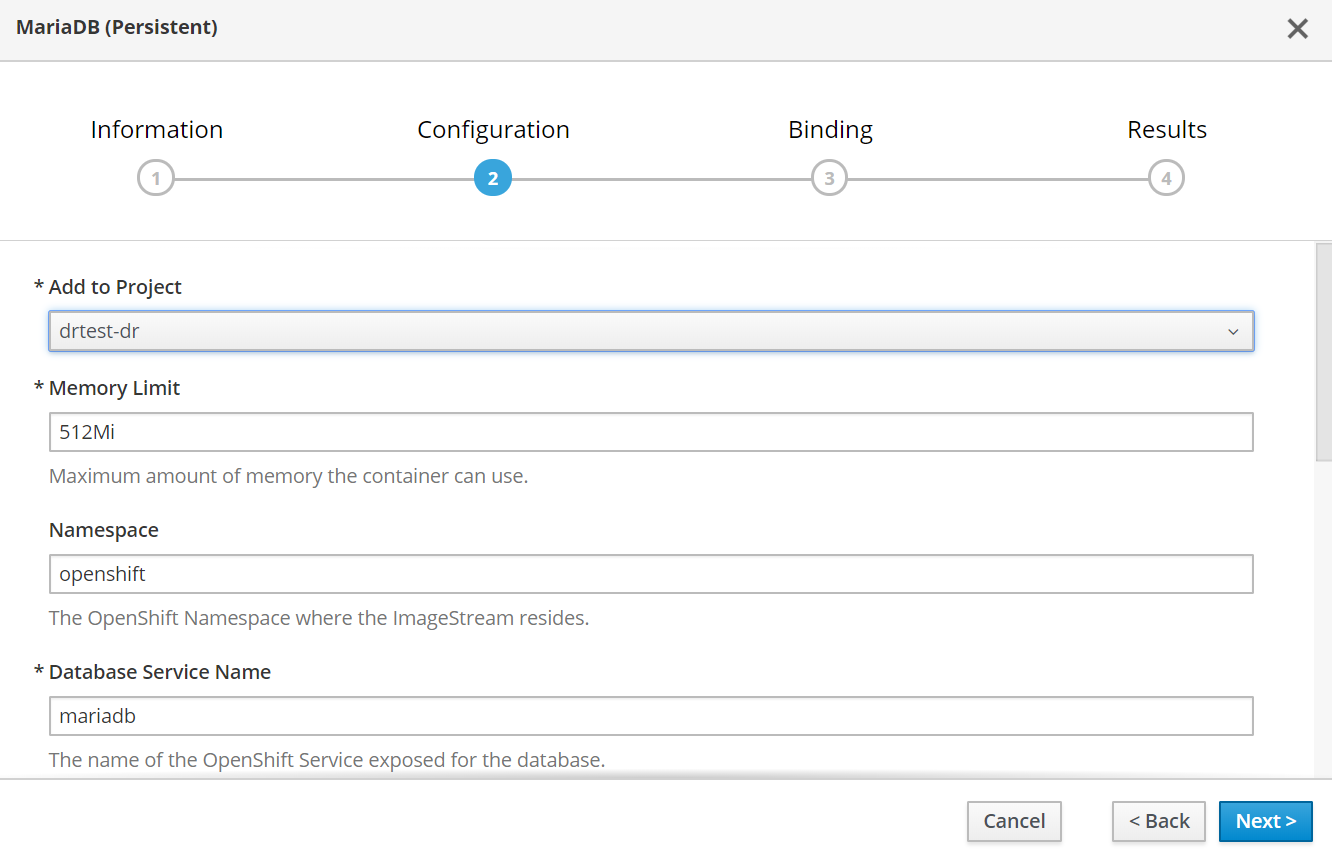
Notice error that the PVC already exists. This is of course expected.
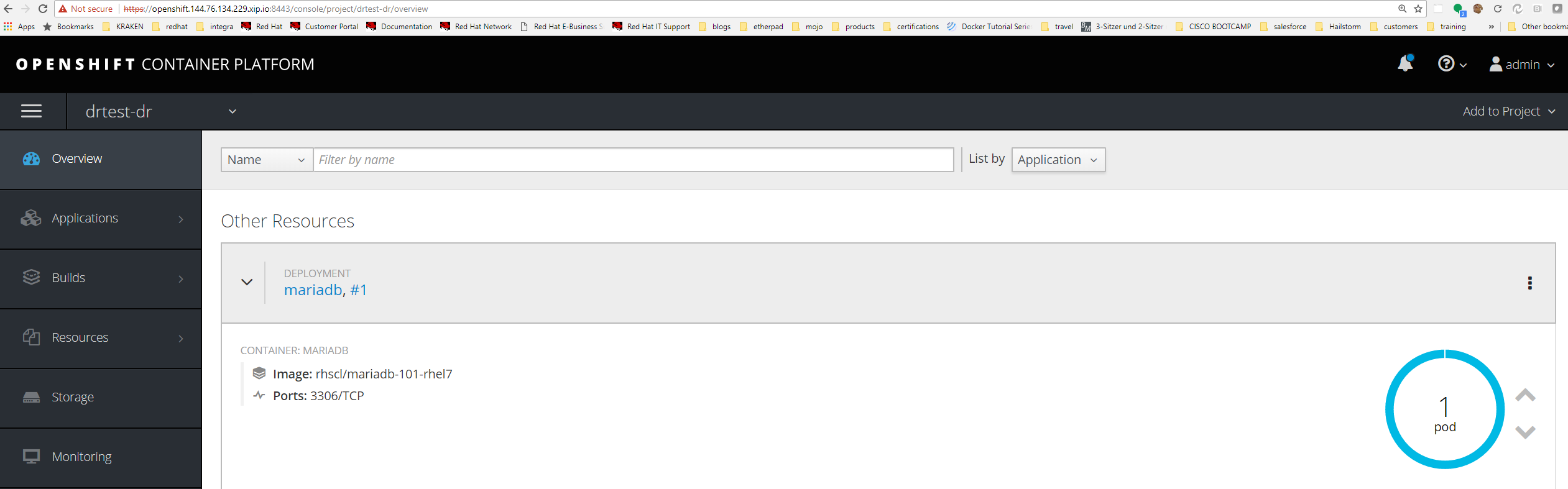
Verify the mariadb pod has started successfully.
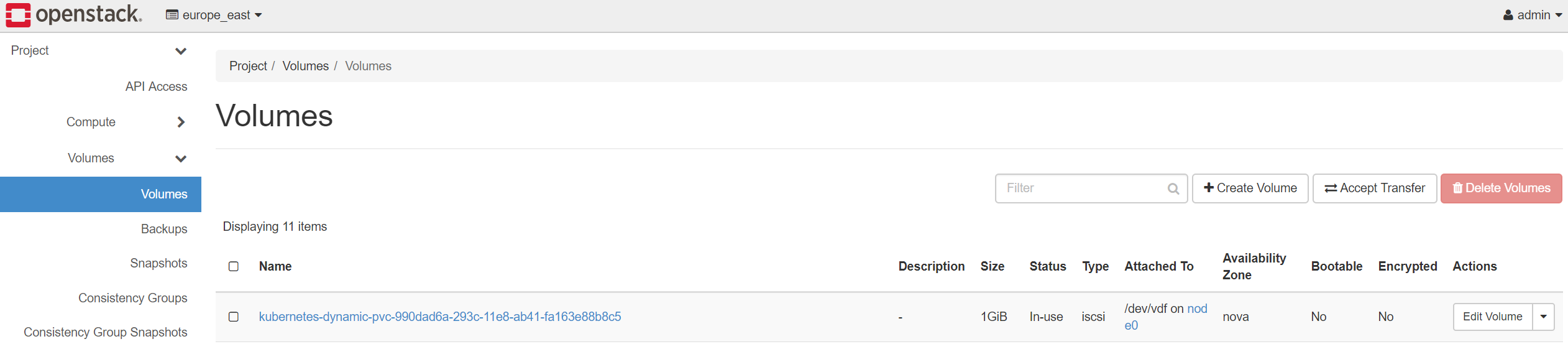
Verify the cinder volume was automatically mounted on the node where mariadb pod started.
Verify the mariadb contains database books and rows with authors as it did on production site.
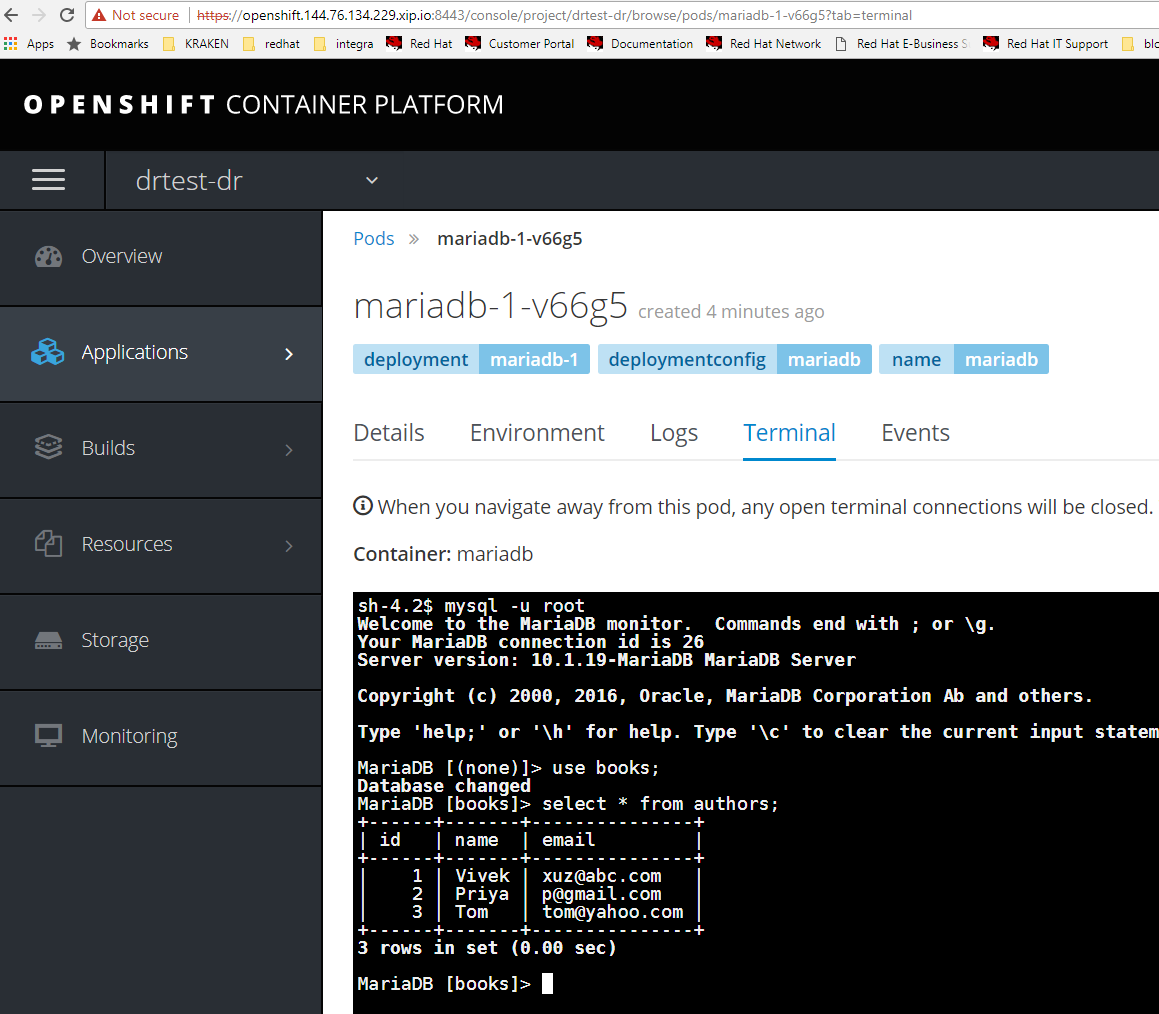
Congrats, that was a DR cut-over between OpenShift clusters.
Summary
In this article we discussed the challenges that organizations have with business continuous. We discussed new ideas and concepts for disaster recovery using containers. Finally a proof-of-concept was provided, showing DR cut-over of a mariadb database across OpenShift clusters.
A new path forward is needed that not only is more cost effective, efficient but also handles disaster recovery and multi-cloud applications, together. Containers are the technology that package our applications, simplifying their deployment and enabling them to be deployed across multiple clouds and infrastructures. IT and DevOps teams have huge reasons to put everything into containers. It is the only way to deal with the level of scale and complexity that exists today. Most recognize this, but unfortunately not all. By providing a container driven disaster recovery solution that is not only better than what exists today, but also at a lower cost, with a lower RTO, could be a driving factor to get traditional non-container applications into containers. I think we can all agree that would be a good thing for everyone. I hope this article serves as a springboard for future architecture concepts relating to disaster recovery and multi-site.
Happy Containerization of Everything!
(c) 2018 Keith Tenzer