
Ceph: the future of Storage

Overview
Since joining Red Hat in 2015, I have intentionally stayed away from the topic of storage. My background is storage but I wanted to do something else as storage became completely mundane and frankly boring. Why?
Storage hasn't changed much in 20 years. I started my career as a Linux and Storage engineer in 2000 and everything that existed then, exists today. Only things became bigger, faster, cheaper, due to incremental improvements from technologies such as flash. There comes a point however, where minor incremental improvements are no longer good enough and a completely new way of addressing challenges is the only way forward.
I realized in late 2015 that the storage industry is starting a challenging period for all vendors but, didn't really have feeling for when that could lead to real change. I did know that the monolithic storage array, built on proprietary Linux/Unix, with proprietary x86 hardware we all know and love, was a thing of the past. If you think about it storage is a scam today, you get opensource software running on x86 hardware packaged as a proprietary solution that doesn't interoperate with anything else. So you get none of the value of opensource and pay extra for it. I like to think that economics like gravity, eventually always wins.
Challenges
There are many challenges facing our storage industry but I will focus on three: cost, scale and agility.
Cost
Linux has become a great equalizer in storage and fueled storage startups over the past 3-5 years, allowing them to quickly build innovative products that challenge traditional vendors. Storage companies not building on Linux, are forced to be operating system companies in addition to storage companies, a distinct disadvantage. Their R&D costs to maintain proprietary storage operating systems reduce overall value, slow innovation and in the end, increase costs. In addition most storage platforms today have high vendor lock-in, offering little choice. You usually can't choose hardware and therefore you are often paying a premium for standard x86. Disks are a great example, typically they cost twice what you would pay through Amazon.
"Oh but our disks are rigorously tested and have a mean time between failure of xxxxxxx so the cost is justified."
No it isn't! We need a new way of thinking, what about if disks failures weren't a big deal, didn't cause impact and storage system automatically adjusted?
While these points may be interesting, at the end of the day, cost comes down to one thing. Everyone is measured against Amazon S3. You are either cheaper than S3 (3 cents per GB per Month) or you have some explaining to do. If we consider small or medium environments, it may be doable with hyper-converged storage, but as soon as scale and complexity come into play (multiple use-cases with block, file and object) those costs explode. If we are talking about large environments, forget it. Even if the cost could get down to S3 range, things wouldn't scale across the many use-cases in a large enterprise.
Scale
Scalability is a very complex problem to solve. Sure everything scales until it doesn't but jokes aside, we have reached a point where scalability needs to be applied more generally, especially in storage. Storage arrays today are use-case driven. Each customer has many use-cases and the larger the customer the more use-cases. This means many types of dissimilar storage systems. While a single storage system may scale to some degree, many storage systems together don't. Customers are typically stuck in a 3-year cycle of forklift upgrades, because storage systems don't truly scale-out they only scale-up.
Agility
The result of many storage appliances and arrays is technology sprawl, which in turn creates technology debt. Storage vendors today don't even have a vision for data management within their own ecosystem, no less interoperating with other vendors. Everything is completely fragmented to point where a few use-cases equals a new storage system.
Storage systems today require a fairly low entry cost for management overhead, but as the environment grows and scales those costs increase, reducing agility. They don't stay consistent, how could they when a unified data management strategy is missing.
Storage systems are designed to prevent failure at all costs, they certainly don't anticipate failure. At scale of course, we have more failures, this in turn correlates to more time spent keeping the lights on. The goal of every organization is to reduce that and maximize time spent on innovation. Automation suffers and as such, it becomes increasingly harder to build blueprints around storage. There is just too much variation.
I could certainly go on and there are other challenges to discuss, but I think you get the picture. We have reached the dead-end of storage.
Why Software-defined?
As mentioned, the main problem I see today is for every use-case, there is a storage array or appliance. The startups are all one-trick ponies solving only a few use cases. Traditional storage vendors on the other hand throw different storage systems at each use-case, cobble them together in some UI and call that a solution. You end up with no real data management strategy and that it is truly what is needed. I laugh when I hear vendors talking about data lakes. If you buy into storage array mindset, you end up at same place, a completely unmanageable environment at scale, where operational costs are not linear but constantly going up. Welcome to most storage environments today.
As complexity increases you reach a logical point where abstractions are needed. Today storage not only needs to provide file, block and object but also needs to interoperate with large ecosystem of vendors, cloud providers and applications. Decoupling the data management software from the hardware is the logical next step. This is the same thing we have already observed with server virtualization and are observing in networking with NFV. The economics of cost and advantages of decoupling hardware and software simply make sense. Organizations have been burned over and over, making technology decisions that later are replaced or reverted because newer better technologies become available in other platforms. Software-defined storage allows an easy introduction of new technologies, without having to purchase new storage system because your old storage was designed before that technology was invented. Finally storage migrations. Aren't we tired of always migrating data when changing storage systems? A common data management platform using common x86 hardware and Linux could do away with storage migrations forever.
Why Ceph?
Ceph has become the defacto standard for software-defined storage. Currently the storage industry is at beginning of major disruption period where software-defined storage will drive out traditional proprietary storage systems. Ceph is of course opensource, which enables a rich ecosystem of vendors that provide storage systems based on Ceph. The software-defined world is not possible without opensource and doing things the opensource way.
Ceph delivers exactly what is needed to disrupt the storage industry. Ceph provides a unified scale-out storage system based on common x86 hardware, is self healing and not only anticipates failures but expects them. Ceph does away with storage migrations and since hardware is decoupled, gives you choice of when to deploy new hardware technologies.
Since Ceph can be purchased separately from hardware, you have choice, not only whom you buy Ceph from (Red Hat, Suse, Mirantis, Unbuntu, etc) but also, whom you purchase hardware from (HP, DELL, Fujitsu, IBM, etc). In addition you can even buy ceph together with hardware for an integrated appliance (SanDisk, Fujitsu, etc). You have choice and are free from vendor lock-in.
Ceph is extremely cost efficient. Even the most expensive all-flash, integrated solutions are less than S3 (3 cents per GB per Month). If you really want to go cheap, you can purchase off-the-shelf commodity hardware from companies like SuperMicro and still get enterprise Ceph from Red Hat, Suse, Ubuntu, etc while being a lot cheaper than S3.
Ceph scales. One example I will give is Cern 30 PB test. Ceph can be configured to optimize different workloads such as block, file and object. You can create storage pools and decide to co-locate journals, or put journals on SSDs for optimal performance. Ceph allows you to tune your storage to specific use-cases, while maintaining unified approach. In tech-preview is a new feature called bluestore. This allows Ceph to completely bypass file-system layer and store data directly on raw devices. This will greatly increase performance and there is a ton of optimizations planned after that, this is just the beginning!
Ceph enables agility. Providing unified storage system that supports all three storage types: file, block and object. Ceph provides a unified storage management layer for anything you can present as a disk device. Finally Ceph simplifies management, it is the same level of effort to manage a 10 node Ceph cluster or a 100 node Ceph cluster, running costs remain linear.
Below is a diagram showing how Ceph addresses file, block and object storage using a unified architecture built around RADOS.
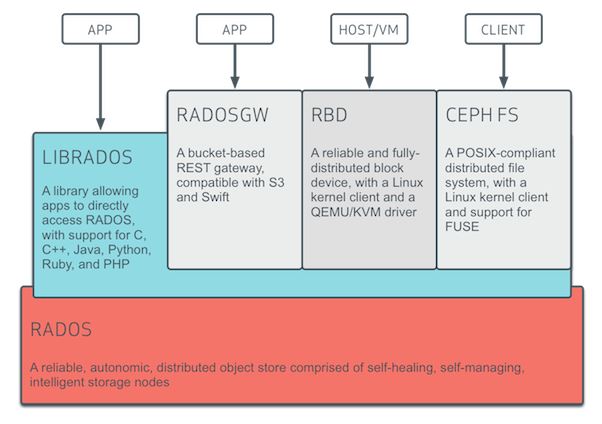
source: http://docs.ceph.com/docs/hammer/architecture
Summary
In this article we spent time discussing current storage challenges and the value of not just software-defined storage but also Ceph. We can't keep doing what we have been doing for last 20+ years in storage industry. The economics of scale have brought down barriers and paved the way for a software-defined world. Storage is only the next logical boundry. Ceph being an OpenSource project is already the defacto software-defined standard and is in position to become the key beneficiary as software-defined storage becomes more mainstream. If you are interested in Ceph I will be producing some how-to guides soon, so stay tuned. Please feel free to debate whether you agree or disagree with my views. I welcome all feedback.
(c) 2016 Keith Tenzer