
Temporal Fundamentals Part VI: Workers
![]()
Overview
This is a six part series focused on Temporal fundamentals. It represents, in my words, what I have learned along the way and what I would’ve like to know on day one.
- Temporal Fundamentals Part I: Basics
- Temporal Fundamentals Part II: Concepts
- Temporal Fundamentals Part III: Timeouts
- Temporal Fundamentals Part IV: Workflows
- Temporal Fundamentals Part V: Workflow Patterns
- Temporal Fundamentals Part VI: Workers
Worker Architecture
Temporal Workers are responsible for Workflow execution. A Workflow is broken down into Workflow and Activity tasks. Workflows and Activities are registered with a Worker and written using the Temporal SDK, in the programming language of choice.
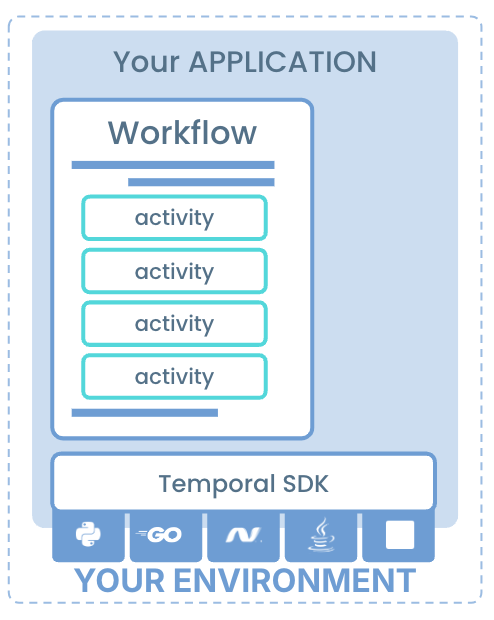
Temporal Workers long poll the Temporal service for tasks, perform execution and return results to the Temporal service. Temporal Workers must poll on a specific Temporal Namespace and TaskQueue. You can have N number of Workers and they can be scaled dynamically.
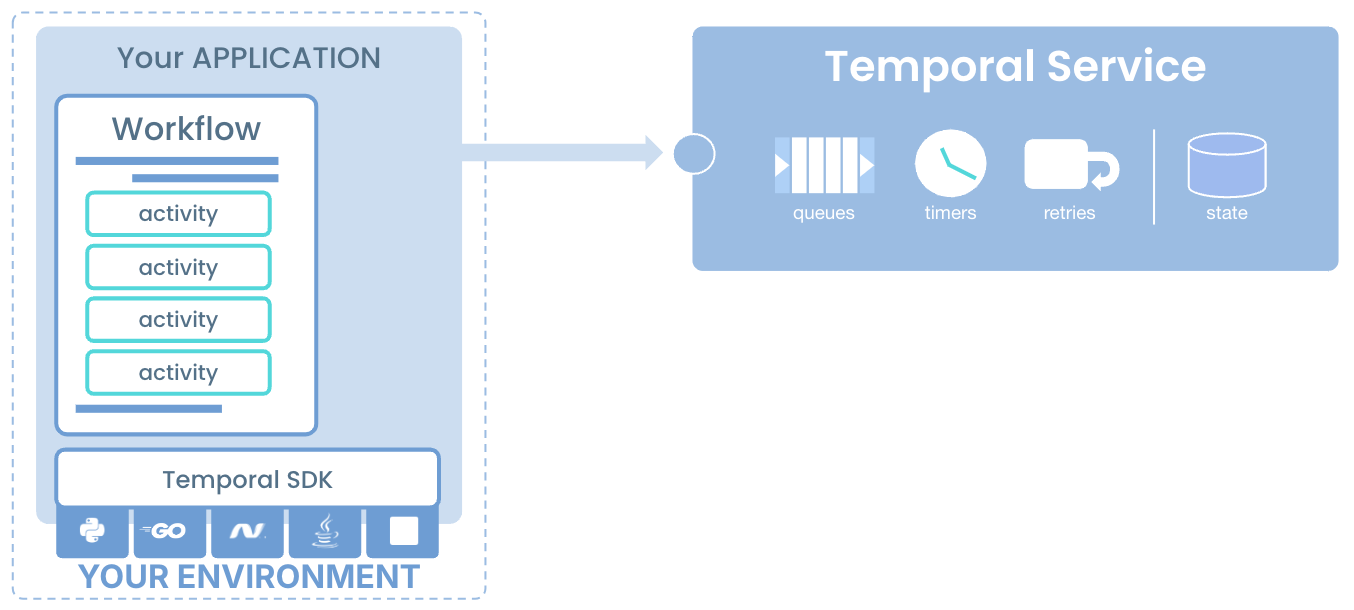
Temporal Workers have a default polling timeout of around 60 seconds. If the timeout is reached, the poll is unsuccessful and a new poll is started. A successful poll, on the other hand, results in a task being matched to a Worker from the matching service.
Workflow and Activity Registration
Up until this point, we have focused on developing Workflows and Activities. Once our Workflows and Activities are developed, they need to be registered to a Worker. A few things to keep in mind:
- Workers can only poll a single TaskQueue and Namespace
- Workers can handle Workflow tasks, Activity tasks or both
- Client connection when using development server or self-host, differs to that of Temporal Cloud, which requires MTLS certificates or API keys.
The below code demonstrates how to create a Worker, setting the TaskQueue, as well as registering Workflow and Activity classes. The client can be switch between localhost and Temporal Cloud, depending on environment settings.
public class AccountTransferWorker {
@SuppressWarnings("CatchAndPrintStackTrace")
public static void main(String[] args) throws Exception {
final String TASK_QUEUE = "AccountTransferTaskQueue";
WorkerFactory factory = WorkerFactory.newInstance(TemporalClient.get());
Worker worker = factory.newWorker(TASK_QUEUE);
worker.registerWorkflowImplementationTypes(AccountTransferWorkflowImpl.class);
worker.registerWorkflowImplementationTypes(AccountTransferWorkflowScenarios.class);
worker.registerActivitiesImplementations(new AccountTransferActivitiesImpl());
factory.start();
System.out.println("Worker started for task queue: " + TASK_QUEUE);
}
}
public class TemporalClient {
public static WorkflowServiceStubs getWorkflowServiceStubs() throws FileNotFoundException, SSLException {
WorkflowServiceStubsOptions.Builder workflowServiceStubsOptionsBuilder =
WorkflowServiceStubsOptions.newBuilder();
if (!ServerInfo.getCertPath().equals("") && !"".equals(ServerInfo.getKeyPath())) {
InputStream clientCert = new FileInputStream(ServerInfo.getCertPath());
InputStream clientKey = new FileInputStream(ServerInfo.getKeyPath());
workflowServiceStubsOptionsBuilder.setSslContext(
SimpleSslContextBuilder.forPKCS8(clientCert, clientKey).build()
);
}
String targetEndpoint = ServerInfo.getAddress();
workflowServiceStubsOptionsBuilder.setTarget(targetEndpoint);
WorkflowServiceStubs service = null;
if (!ServerInfo.getAddress().equals("localhost:7233")) {
// if not local server, then use the workflowServiceStubsOptionsBuilder
service = WorkflowServiceStubs.newServiceStubs(workflowServiceStubsOptionsBuilder.build());
} else {
service = WorkflowServiceStubs.newLocalServiceStubs();
}
return service;
}
Deployment
Each Worker is a single process. Typically for Kubernetes, each Worker process would run in its own container/pod. Scaling is done bu increasing replicas, thus creating more pods and worker processes. A single machine can of course run multiple Worker processes. This is also possible within the same pod in Kubernetes.
For Autoscaling Workers, we can use the built-in Autoscaler based off TaskQueue metrics or create our own Autoscaler using SDK metrics such as, Workflow/Activity ScheduleToStart latencies.
Example Dockerfile for Java Worker
# Use an official Gradle image from the Docker Hub
FROM --platform=linux/amd64 gradle:jdk17-jammy AS build
# Set the working directory
WORKDIR /home/gradle/project
# Copy the Gradle configuration files first for leveraging Docker cache
# and avoid the downloading of dependencies on each build
COPY build.gradle settings.gradle gradlew ./
# Copy the gradle wrapper JAR and properties files
COPY gradle ./gradle
# Copy the source code
COPY ./core ./core
# Now run gradle assemble to download dependencies and build the application
RUN chmod +x ./gradlew
RUN ./gradlew build
# Use a JDK base image for running the gradle task
FROM amazoncorretto:17-al2-native-headless
WORKDIR /app
# Copy the build output from the builder stage
COPY --from=build /home/gradle/project/build /app/build
# Copy the source code
COPY --from=build /home/gradle/project/core /app/core
# Copy the gradlew and settings files
COPY --from=build /home/gradle/project/gradlew /home/gradle/project/settings.gradle /home/gradle/project/build.gradle /app/
COPY --from=build /home/gradle/project/gradle /app/gradle
# Run the specified task
CMD ["sh", "-c", "./gradlew -q execute -PmainClass=io.temporal.samples.moneytransfer.AccountTransferWorker"]
Below shows example of Kubernetes Worker deployment.
apiVersion: apps/v1
kind: Deployment
metadata:
name: temporal-money-transfer-java-worker
labels:
app: temporal-money-transfer-java-worker
spec:
replicas: 3
selector:
matchLabels:
app: temporal-money-transfer-java-worker
template:
metadata:
labels:
app: temporal-money-transfer-java-worker
spec:
serviceAccountName: cicd
containers:
- name: worker-workflow
image: ktenzer/temporal-money-transfer-java-worker:latest
imagePullPolicy: Always
env:
- name: ENCRYPT_PAYLOADS
value: "true"
- name: TEMPORAL_ADDRESS
value: ktenzer-test-1.sdvdw.tmprl.cloud:7233
- name: TEMPORAL_NAMESPACE
value: ktenzer-test-1.sdvdw
- name: TEMPORAL_MONEYTRANSFER_TASKQUEUE
value: MoneyTransferSampleJava-WaaS
- name: TEMPORAL_CERT_PATH
value: /etc/certs/tls.crt
- name: TEMPORAL_KEY_PATH
value: /etc/certs/tls.key
volumeMounts:
- mountPath: /etc/certs
name: certs
volumes:
- name: certs
secret:
defaultMode: 420
secretName: temporal-tls
SDK Metrics
Temporal Workers, if configured, emit important metrics for understanding performance and performing fine-tuning of workers. Workers can be configured to support Prometheus, StatsD and even M3.
An example configuration for Prometheus in Java can be found here.
In Kubernetes, Temporal workers can be scrapped by simply defining a service to expose the metrics endpoint and a service monitor to scrape periodically into Prometheus.
Metrics Service
apiVersion: v1
kind: Service
metadata:
labels:
app: temporal-metrics-worker
name: metrics
spec:
internalTrafficPolicy: Cluster
ipFamilies:
- IPv4
ipFamilyPolicy: SingleStack
ports:
- name: metrics
port: 8077
protocol: TCP
targetPort: 8077
selector:
app: temporal-metrics-worker
sessionAffinity: None
type: ClusterIP
status:
loadBalancer: {}
Service Monitor
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
app: temporal-metrics-worker
name: metrics-monitor
spec:
endpoints:
- port: metrics
interval: 15s
scrapeTimeout: 14s
namespaceSelector:
matchNames:
- temporal-metrics
selector:
matchLabels:
app: temporal-metrics-worker
Worker Tuning
Having Worker and Temporal service (server or Cloud) metrics is a pre-requisite to any tuning or optimization. Before jumping into Worker metrics, it is good to look at Worker Sync/Match Rate. This metric is emitted for the Temporal Service. While it doesn’t show if a worker is well tuned, it does show if workers are able to keep up with the rate of work being generated by the Temporal service. It is recommended to have >= 95% Sync/Match rate. Having a poor Sync/Match rate is an indication that Worker tuning may be required.
Temporal Workers have resource constraints: CPU, Memory and IO.
CPU
Workers execute Workflow and Activity tasks concurrently. More work means more CPU is required. First we should identify how much work a Worker should do. Just because we can do more, doesn’t mean that is preferred, for example protecting a downstream service. How much work a Worker can do is a function of CPU resources assigned to worker and the Worker settings:
- MaxConcurrentWorkflowTaskExecutionSize
- MaxConcurrentActivityTaskExecutionSize
To determine the right settings, we should aim to utilize as much of the CPU as possible without going above 80% utilization. However, when doing so we need to ensure metrics schedule-to-start latencies (time tasks are waiting to be executed) remain low.
- activity_schedule_to_start_latency
- workflow_task_schedule_to_start_latency
In addition we need to ensure that our Workflow and Activity task slots (TaskExecutionSize) don’t get close to 0 by monitoring the task slots metrics bucket.
- worker_task_slots_available {worker_type = WorkflowWorker}
- worker_task_slots_available {worker_type = ActivityWorker}
Finally, measuring the task execution latency, can help identify problems with our code or downstream dependencies, especially for CPU intensive operations.
- workflow_task_execution_latency
- activity_task_execution_latency
Memory
Workers cache Workflow event histories as an optimization so that Workflow replay (which can be expensive) only happens when there is a failure (Worker dies, etc). However, not having enough memory or cache slots can mean Worker cache is evicted which then causes additional, unneeded Workflow replays. This is controlled by the setting:
- MaxCachedWorkflows/StickyWorkflowCacheSize
To determine if memory is optimized for caching of Workflows we can look into the cache metrics:
- sticky_cache_total_forced_eviction
- sticky_cache_size
- sticky_cache_hit
- sticky_cache_miss
These metrics show the size of our cache, the hit/miss ratio and when forced evictions happen. If we see forced evictions and lots of misses, we can increase the cache size, after verifying sufficient free memory. We should aim to stay below 80% memory utilization.
If we are seeing lots of cache misses, looking at replay latency would be recommended.
- workflow_task_replay_latency
Workflow replay requires downloading the Workflow event history to Worker and then replaying it. This can be improved by tuning CPU but also by reducing event history size, for example by utilizing continue-as-new or segmenting Workflow using Child Workflows.
IO
Workers poll for Workflow and Activity tasks. Each has its own set of pollers. How much work a Worker can grab at any one point, is function of how many pollers are defined in Worker settings and overall network IO:
- MaxConcurrentWorkflowTaskPollers
- MaxConcurrentActivityTaskPollers
Optimizing requires looking at the following metrics buckets:
- num_pollers {poller_type = workflow_task}
- num_pollers {poller_type = activity_task}
- request_latency {namespace, operation}
Additional documentation for both SDK (Worker) and Service (Server/Cloud) metrics can be found here.
Auto Tuning
The Temporal Worker supports auto-tuning. You can do auto-tuning of task slots based on fixed slot size, resources or even custom. The resource based auto-tuner will for example provide additional slots until it reaches the set limit for CPU and Memory.
Example of resource based auto-tuning for Java Worker setting CPU and Memory utilization to 80%.
WorkerOptions.newBuilder()
.setWorkerTuner(
ResourceBasedTuner.newBuilder()
.setControllerOptions(
ResourceBasedControllerOptions.newBuilder(0.8, 0.8).build())
.build())
.build())
Additional documentation on Worker performance can be found here
Data Converter
The Data Converter is a component of the Temporal SDK, handling serialization and encoding of data from your application, to payloads sent to the Temporal service. It has several use cases:
- Encryption / Decryption
- Compression
- Custom Serialization/Deserialization
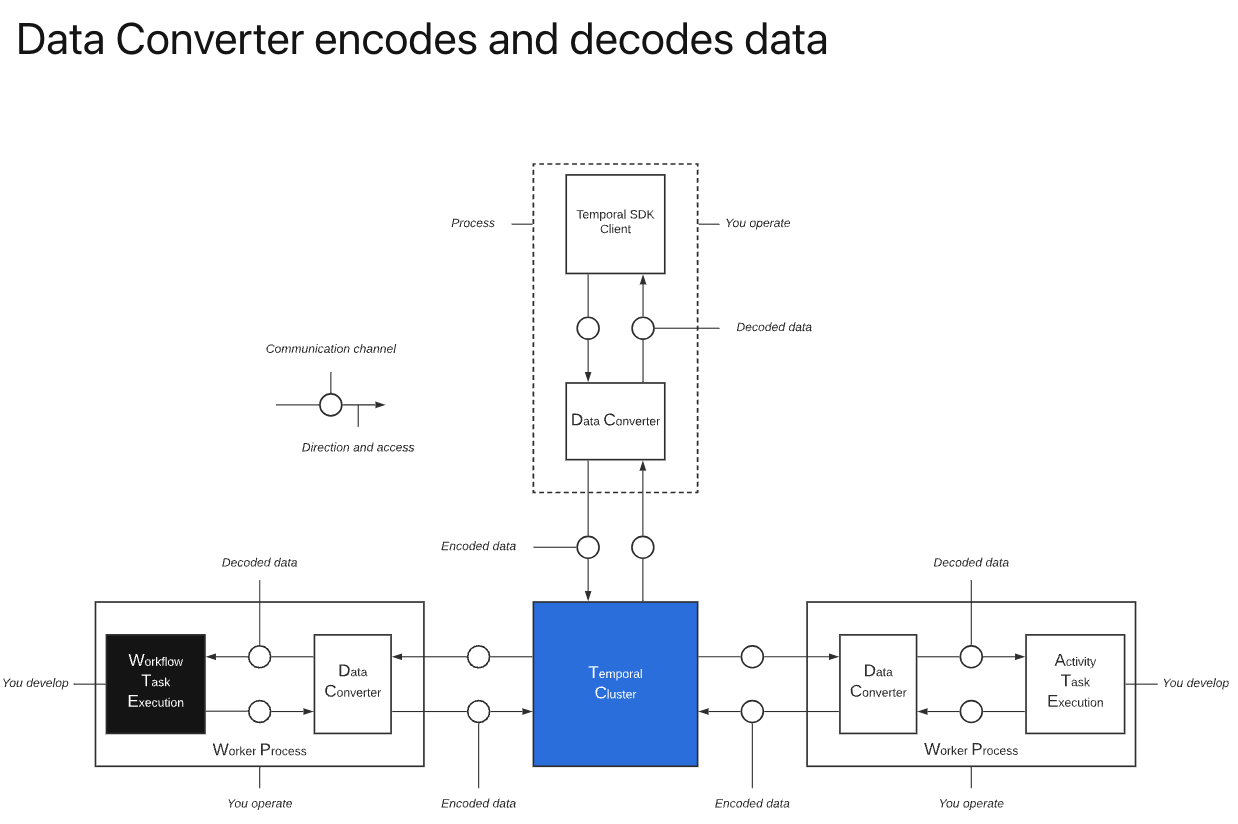
The Data Converter is widely used to ensure sensitive data sent into payloads via Workflow or Activity inputs is secure. This is accomplished by allowing developers to define their own encryption codec, using their own keys. The Temporal service never accesses a Worker directly, nor has access to the keys or encryption codec. As such all payloads sent/received to/from the Temporal service are encrypted/decrypted within the Worker. This provides a clean security model with clear areas of responsibility and control.
The Data Converter is configured in the Worker WorkflowClientOptions.
WorkflowClient client =
WorkflowClient.newInstance(
service,
WorkflowClientOptions.newBuilder()
.setDataConverter(
new CodecDataConverter(
DefaultDataConverter.newDefaultInstance(),
Collections.singletonList(new CryptCodec())))
.build());
Summary
The Temporal Worker is where Workflows and Activities are executed. In this article we reviewed the Temporal Worker, including configuration and deployment example for kubernetes. We demonstrated how to configure metrics and approach Worker tuning. Finally, we discussed the Data Converter and how it can be used to secure sensitive payloads.
(c) 2024 Keith Tenzer