
Containers in Large IT Enterprises

Overview
As this will be the last article of 2017 I wanted to do something different and get away from my typical how-to guides (rest assured I will continue doing them in 2018). Over the past year, I have engaged in a lot of conversation with many large organizations looking to adopt or increase their container footprint. In this article I will share my thoughts on what I have learned from those discussions. We will discuss the impact of containers in large IT organizations. Understand the difference between container technology and container platform. Look into the integration points a container platform has into the existing IT landscape and finally discuss high-level architectural design ideas.
This article should serve as a good starting point for IT organizations trying to understand how to go about adopting container technology in their organization.
Impact of Containers in Large IT Organizations
Containers are of course just a technology, but it is a technology at the center of the DevOps movement. When talking about the impact of containers we also must discuss DevOps. Currently about 70% of development teams are using agile principles. However only about 30% of operations teams are using those same principles. This is unfortunately a major gap and a huge challenge for the enterprise. To understand things further, we need to take a closer look into how many IT organizations mange service.
A large majority of enterprise IT organizations are using ITIL (a framework for IT service management). One of the key processes in ITIL is of course change management. In many organizations change management is a painful process involving meetings, approvals and getting things done can at times, feel like pulling teeth. This is not the fault of ITIL or even IT but rather the application architectures of the past and how ITIL processes were implemented to deal with those monolithic dragons. Basically for the last 20 years, developers have been throwing code over the wall to their ops colleagues who in turn, had to deploy the code on infrastructure that differed in every way imaginable from that of where application testing occurred. The result was a lot of trial and error and certainly lots of frustration. ITIL however helped safeguard the process of change in such a chaotic environment so that a service could still meet its SLA.
Today developers are not only adopting agile but practices like continuous delivery, creating incredibly fast release cycles (change) and operations simply cannot keep up and even if they could a developer releases a new version in a day, where the ITIL change process (without complete automation) may take multiple days or even weeks. As such, how can a large IT organization move forward given this situation?
Well one view that got a lot of traction from Gartner (Bi-modal IT) is one option. Basically your current IT is for running stable, long running applications that don't change much where the current processes, structure and culture fit (mode 1). A new organization is created that adds capability for fast releasing, innovative, agile applications (mode 2). In fact this is what many organizations have chosen to do and why we now see entire new organizations in enterprises called *something* "Digitalization". Makes sense but is this the right approach?
I don't think so, let's be honest, it is very short sighted. We talk a lot about digital transformation, but how is creating a new organization a transformation? Yes it will produce some short-term results and provide a bi-modal capability (if you want to call i that) but at what cost? You now are running two independent IT organizations, that probably don't talk to each other, are completely isolated and services, resources, knowledge between these organizations aren't leveraged. Worse your new bi-modal organization isn't leveraging past 20 years of expertise in running IT. To put it another way, you are forking your IT organization.
Instead of building a new greenfield digital organization, why not take a long-term strategic approach? You won't be able to change everything overnight but at least you can start by creating a new group within your existing IT organization that is building applications using DevOps practices and providing a platform-as-a-service is an integral part to mode 2 service IT could offer.
Container Technology vs Container Platform
When discussing containers it is important to understand difference between technology and platform. Technology simply applies an action to a human need. To make DevOps work we needed a way to package applications so the application version and its runtime stayed consistent, through the application lifecycle, across potentially varying infrastructure platforms. A platform is a group of technologies that is used as a base from which other applications, processes or additional technologies are developed. In other words a platform is an environment for providing business capabilities and needs that generate business value for an organization, hopefully resulting in additional revenue. Below is a chart that further compares technology to platform focusing on container technology vs container platform.
| Capability | Technology | Platform |
|---|---|---|
| Container Packaging (Docker) | ||
| Container Orchestration (Kubernetes) | ||
| Container Runtime Environment (Operating System) | ||
| Centralized Logging | ||
| Monitoring & Reporting | ||
| Security | ||
| Networking | ||
| Storage | ||
| Performance | ||
| Service Catalog | ||
| Registry (Container Images) | ||
| CI/CD Pipeline and Release Management |
While it would seem obvious that if you are not Google, Amazon or Microsoft you would buy a container platform that provides the above capabilities, allowing resources to focus on delivering unique business value and not solving IT problems that have already been solved. Do-it-yourself (DIY) container platforms as such, should not be considered for large IT enterprises focused on a wide variety of containerized applications and use cases. So what options exist for large enterprises?
- Container platform from cloud providers (Google, Amazon, Microsoft)
- Container platform from vendor (Red Hat and others)
The leaders are clearly Google and Red Hat and this is also validated by upstream activities.
If you are willing to have lock-in at infrastructure level, don't want to leverage your existing IT and don't need on-premise capabilities, cloud provider such as Google (GKE) is the best choice. Otherwise Red Hat and OpenShift are easily the best choice if a multi-cloud, including possibly on-premise is a requirement.
Considerations for Integrating Container Platform into the Existing Ecosystem
As discussed, the goal should not be to build a completely new organization that adopts DevOps, Agile principals and containerization but rather, add the capability to the existing organization. This allows the entire organization to benefit and not just the new cool digitalization organization or whatever it is called. Of course it is easier said than done, most organizations shy away because it is in fact hard work and arguably carries more risk. There is a natural resistance to change, existing ITIL process and other barriers need to be changed to clear the path for containerization. A great place to start would be completing a DevOps maturity assessment. Such an assessment could provide valuable information on where to focus and how to move forward with IT transformation. If done right, I am convinced this approach could deliver results just as fast as the Gartner Bi-modal (multiple organizational) method while providing huge benefits for the long-term.
You have decided to embrace microservices, DevOps and containers. You have completed a DevOps assessment, what now? Well the next step is to find a true DevOps champion, someone that won't be discouraged, can lead, has a vision, will breakdown the barriers and deliver a minimum viable platform for enabling mode 2 applications. The champion needs to identify groups or projects within organization that already have a DevOps mindset, are potentially already building applications in direction of microservices and would be willing to take part in a new shared platform as a pilot project. This can best be done in a series of discovery workshops where time can be spent learning about the applications, processes and most important, the people.
Once the pilot projects or early adopters have been identified it is time to turn attention toward the platform. The nice part about leveraging existing IT is you have a wealth of knowledge about security, networking storage and processes for managing IT services. You also have strong knowledge in IT service management, which is very advantageous. Only the processes and cultural mindsets need to be tweaked in order to fit into DevOps and eventually containers into existing organization. Now on to the technology!
Registry
The container platform registry is probably the best place to start. The registry contains all container images. Since containers, at least Docker containers are immutable, every change (new release, library) results in new container image that has to be updated in the registry. The registry plays a key role in ITIL as part of the definitive media library (DML). The good news is that you don't need to dramatically change what you are doing in regards to DML. Container images that are built can be for example, added to existing DML automatically through a CI/CD pipeline using Jenkins or similar tooling. Images can be scanned and an automatic approvals can be generated based on well-defined criteria. From here applications packaged into containers can be rolled out into further lifecylce stages across the platform, again automatically. Another benefit, many IT organizations already understand what content needs to be checked and have processes and tools in place to do so.
Container Images
Container images is one area where I see a lot of confusion. Most organizations try to make either development or operations responsible for what is inside a container. Unfortunately this does not work. The container consists of the application runtime plus Base OS (operations) and the application itself (development). Both groups share equal responsibility. This concept of shared responsibility didn't really exist in the past, we always had a clear boundary between development and operations. This is one reason why containers are referred to as a DevOps enabling technology, it sort of forces the issue. Since Docker images are layered, operations can provide base images (OS runtime) and developers can consume those images and layer their application on top. This allows both groups to work independently but share responsibility, the cornerstone of DevOps.
Container Runtime Environment
A container platform requires a container host and an Operating System capable of running containers. Containers do not contain, meaning they do not enforce any security that would prevent a compromised container from accessing another on a given host. Due to nature of microservices and containers, we have a lot of them running on a host, maybe 100s. If we think about security, say an HR application and a customer facing application. Considering both running on same host, we could have an issue from security perspective. This is where choosing a rock solid enterprise Operating System that leverages SELinux and other such technologies is absolutely critical. Most containers that are coming from Docker Hub run as root and are not well maintained, meaning they come with security vulnerabilities. This is a recipe for disaster in the enterprise. A secure container operating system while critical, can only addresses part of the problem however. A platform around it is needed to handle lifecycle, maintenance, verification and scanning of container images that can also automate needed ITIL process. While containers should never run as root, it may be required. In general, containers running as root should be isolated from non-root containers through the container platform, if required on separate physical servers. Again here we need much more than just technology.
Networking
Container orchestration requires networking. Not only do physical container hosts need to be connected, an overlay is needed to connect the container network segment of the physical container host to the container network segment of another physical container host. In addition there are plenty of security concerns that must be addressed. Containers must be isolated from one another (East/West). Kubernetes provides a namespace but without a proper SDN it will not be possible to isolate traffic. In addition within a namespace isolation between containers may also be required. Egress and Ingress (North/South) traffic also needs to be isolated in the enterprise. The service layer of container platforms acts as a proxy (handling service discovery and service load balancing) but this means that if an external service or user has access to one container, it has access to potentially all. Similarly, if a container can access an external service, so can all the other containers. Outbound traffic goes out the physical interface of a container host with the IP of that interface. Finally there are physical network barriers such as DMZ vs internal, where traffic must be isolated across physical network boundaries.
Storage
Some container platforms don't offer data persistency at all. One of the major advantages of Kubernetes as a technology is the integration with storage through the storage provisioner. Storage can be provisioned by the developer dynamically and storage is also provisioned or de-provisioned on the storage system. This allows storage to work in a DevOps model as waiting for tickets would clearly create an unwanted barrier. Most of storage today can be used in context of a container platform. I am not saying it should be used, there are also new approaches to storage that need to be considered. The biggest consideration here is traditional storage vs local storage vs container native storage.
Architectural Design
Designing a enterprise container platform requires a lot of upfront planning, design and discovery workshops. It is critical to understand requirements as well as limitations from security, identity management, networking, storage and compute standpoint. A single point of contact should be identified in all critical infrastructure groups. In addition pilot projects and their requirements around CPU/MEM as well as performance expectations should be well documented.
Next we want to consider critical container services such as ETCD, Scheduler, API, UI/CLI, Logging, Metrics, Docker Registry, Router and Container Storage.
ETCD - Stores state of cluster and persists changes dynamically Scheduler - Distribute and redistribute container workloads dynamically API - Inter-cluster communication and end-user actions (API/CLI/UI) Logging - Central logging for all applications running on platform Metrics - Performance data for all applications running on the platform Docker Registry - Store docker images and source-to-image streams Router - Proxy traffic from application endpoint (URL) to service Container Storage - Provides storage for container persistence
Masters
Services like etcd, scheduler and API need to access all nodes where containers are running. These services are control in nature. As such it makes sense to group them into a role called master. Since these services are all active/active having three masters would be most beneficial from availability and scalability perspective. For a really large container cluster it may also be an option to deploy etcd service on it's own nodes. It is also important to ensure all masters have low and predictable latency for inter-master communications, nothing higher than 100ms, ideally lower.
Infrastructure Nodes
Common services that applications running on the platform share should be provided by infrastructure nodes. Since these services need to be available and scalable as well as have their own performance considerations it makes sense to separate them on infrastructure nodes. Infrastructure nodes are just like normal application nodes but dedicated to providing shared services useful for applications. Typical services include logging (Elasticsearch, Fluentd, Kibana), metrics (Prometheus or Hawkular), Docker Registry (docker) and Router (HA-proxy). For infrastructure nodes a three node cluster is desired for logging and metrics. These services typically use mogodb or a distributed no-sql datastore that would benefit greatly from three nodes.
Additional infrastructure nodes may also be needed for segregated network zones. A router (ha-proxy) is typically required to proxy traffic from an application endpoint or URL to the service running in Kubernetes. This solution at least allows external URLs to be created dynamically without having to update load balancers or DNS manually. As such where application nodes exist a router or infrastructure nodes must also exist. Finally, moving infrastructure nodes into physical network zones also allows for traffic isolation. Applications within a given zone are only reachable through the infrastructure nodes assigned to that zone. In case of zone specific infrastructure nodes, two is recommended since only the routers are typically running and only HA is needed.
Application Nodes
Applications should be dedicated to their own nodes and not be run on masters or infrastructure nodes. Application nodes can run on bare-metal nodes, Virtual Machines or a mix. Looking at security it may also be important to isolate applications from one another on separate physical nodes. As discussed this may be required for root vs non-root applications or application types HR vs customer facing. Application nodes can be shared or dedicated, depending on the consumption models being offered.
Storage Nodes
Ideally storage would be provided by the application nodes. This would bring compute and storage closer together. Application nodes could provide local disks (SSDs) and using a software-defined storage, those disks could be abstracted providing a layer of management that integrates with the container platform. Of course it is also possible to run dedicated storage nodes. The downside here is that a shared storage platform adds more complexity and moved data further from compute. Today there many possibilities but storage is still in its early days. Pay attention to the capabilities, not all storage systems are well integrated and very few offer required enterprise capabilities like growing existing volumes.
Load Balancers
In order handle external application traffic, content related capabilities, dynamic discovery, load balancers are required. There are various solutions both software and hardware based. The most important decision is likely where to do TLS termination. It can be done at load balancer, at the routing (proxy) layer or application. Termination beyond the load balancer usually requires SNI. Without SNI options are rather limited. The load balancer may also be required to support websockets depending on the UI or other features of container platform. A lot of time should be spent understanding load balancer requirements up front.
Finally lets look at an example architecture. For starters, orientating design toward network boundaries is certainly a good starting point. With something as dynamic as containers, quite a lot of thought is required to avoid a slow change process that would severely limit the overall potential.
Below is an example of a high-level design based on network boundaries and some of the concepts already discussed.
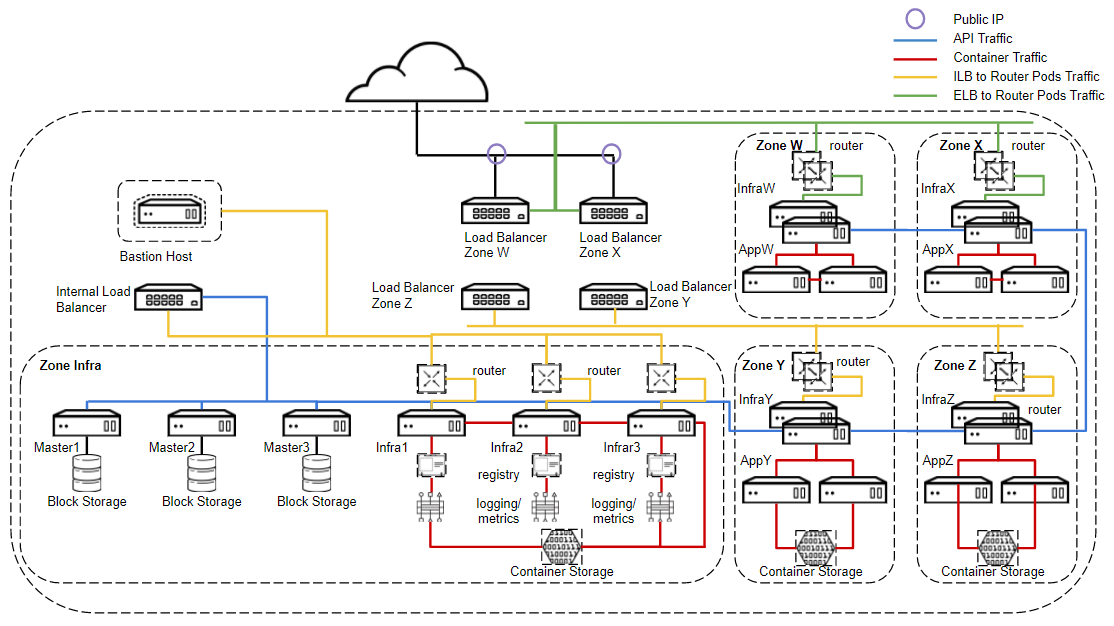
The design takes into account four physical network zones. DMZ production (Zone W), DMZ Test (Zone X), Internal production (Zone Y), Internal Test (Zone Z). There are strict physical firewalls between all zones. A management zone is created (Zone Infra) so that the masters can communicate to all nodes (required) and so shared infrastructure services are also available to all nodes. These ports must be opened through the firewall to W, X, Y, Z zones from the infra zone. In this example storage is only required in three zones (Zone Infra, Zone Y and Zone X). In this case due to segregation at network layer and application locality within zone it makes most sense to run container storage in each zone, where required. It would however also be possible to design a shared storage environment across the zones via a separate, isolated storage network but due to complexity, security and locality this would not be my recommendation in most scenarios.
Isolating Egress
When accessing external services, outside platform (a database), containers will route the traffic out the nodes physical interface. Packets will be sent with physical IP of node. This means if you open an external database up to the node physical IP, all containers running on given node can now also access the database. This is not ideal. The main solution is to deploy an egress router (proxy). This is a special router type where a gateway IP can be configured that has access to external service (database). Containers are given access to egress router through labeling of service. Containers will have a second interface configured using macvtap which can access the egress router. Traffic is then routed to external service (database) over egress router instead of the node physical IP.
Isolating Ingress
Since typically routers are shared, any user that can access one application behind a router can access another. This may not always be desired. Either an external IP can be used directly in the container or an application can have it's own ingress router (proxy) where specific IPs can be defined. The ingress router solution is much more flexible and dynamic. Similar to egress router, this allows for normal ACLs to be configured in order to limit scope of access.
Summary
In this article we discussed some of the impacts containers have on large IT organizations. Containers go far beyond a packaging format for applications. Culture, process and people must be addressed when implementing containers. Containers are only a technology, a platform is needed to enable DevOps and take full advantage of containerization. Some enterprises choose to build a completely new organizations to enable DevOps and containerization but although this may be the fastest way to get going, it remains rather shortsighted. Embracing DevOps culture and container technology into existing organization through a platform that integrates with traditional IT produces the best long-term results. Architecting an enterprise container platform requires many upfront discovery workshops and well defined pilot projects. Identifying contacts across all infrastructure teams as well as bringing them into container conversation is a critical early success factor. I wish you best of luck on your journey to containerization and hope this article provided some help in getting started!
Happy Containerizing!
(c) 2017 Keith Tenzer