
Getting Started with Machine Learning

source: https://news.sophos.com/en-us/2017/07/24/5-questions-to-ask-about-machine-learning/
Overview
In this article we will dive into machine learning. We will begin by understanding the concept, then look at some of the use cases, requirements and finally explore a real world scenario using a demo application. Machine learning has the potential to dramatically change our lives, jobs and influence decision making on a scale that has never been seen before. It is one of the most exciting and also scary technological advancements to ever come around. It is the future but is also happening right now which is why there couldn't be a better time to get started than today.
Understanding Machine Learning
In order to properly understand machine learning we need to consider artificial intelligence. The goal of AI is to create machines, built from computer programs that have cognitive capabilities, are able to analyze their environment and make decisions like a human would. AI is a huge field and there is a lot of topics within it but ultimately it is about making decisions cognitively. Machine learning as such is the foundation or building block of AI. Machine learning primarily is concerned with making the right decision based on learning. Deep learning is a subset of machine learning and often confused with the latter. Deep learning applications are basically the same, where they differs is around how they learn. Deep learning is predicative, understands accuracy and when given metrics or guidelines is able to learn on it's own without supervision from humans. The below diagram shows how machine learning and deep learning fit into artificial intelligence.
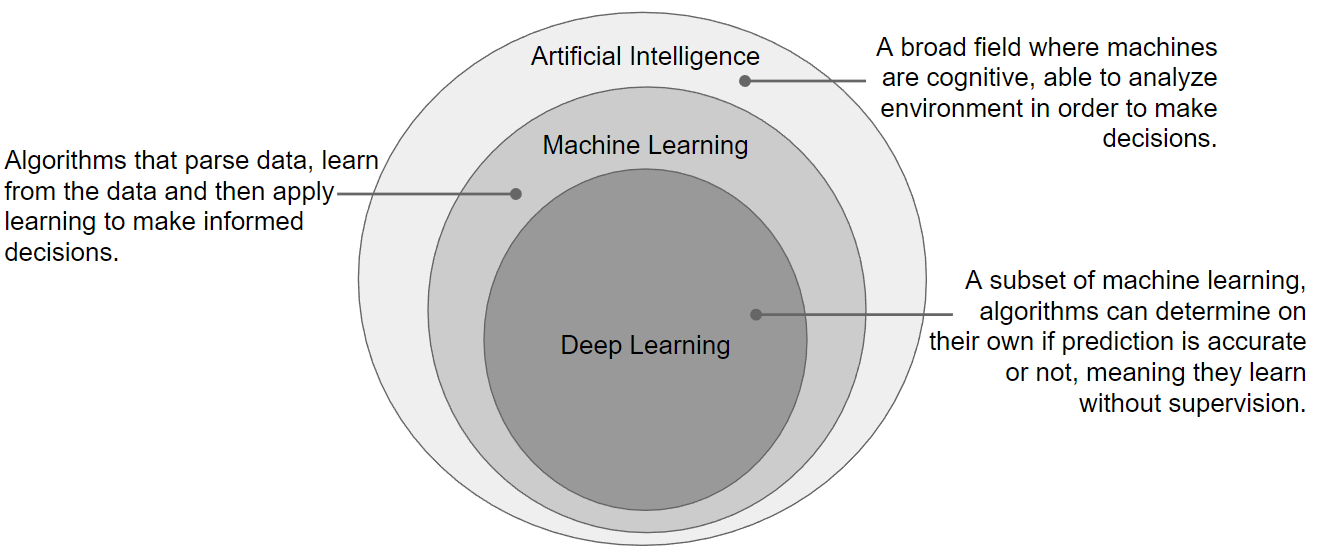
The capability of deep learning being able to learn on it's own is made possible by neural networks. A neural network is composed of many layers and weighted connections, that when given an input attempts to find the best possible output. The algorithms are within the layers and responsible for determining the output. This is done by weighting, prediction and measuring accuracy against metrics. A training set of data is then used to run a training cycle and build the neural network connections. The end result is a trained model with it's own learned rule-set, that would be used by an application to create a business value. I like to refer to the phase of using a trained model as the professional phase.
The below diagram shows a basic workflow for machine learning with both the training and professional phases.
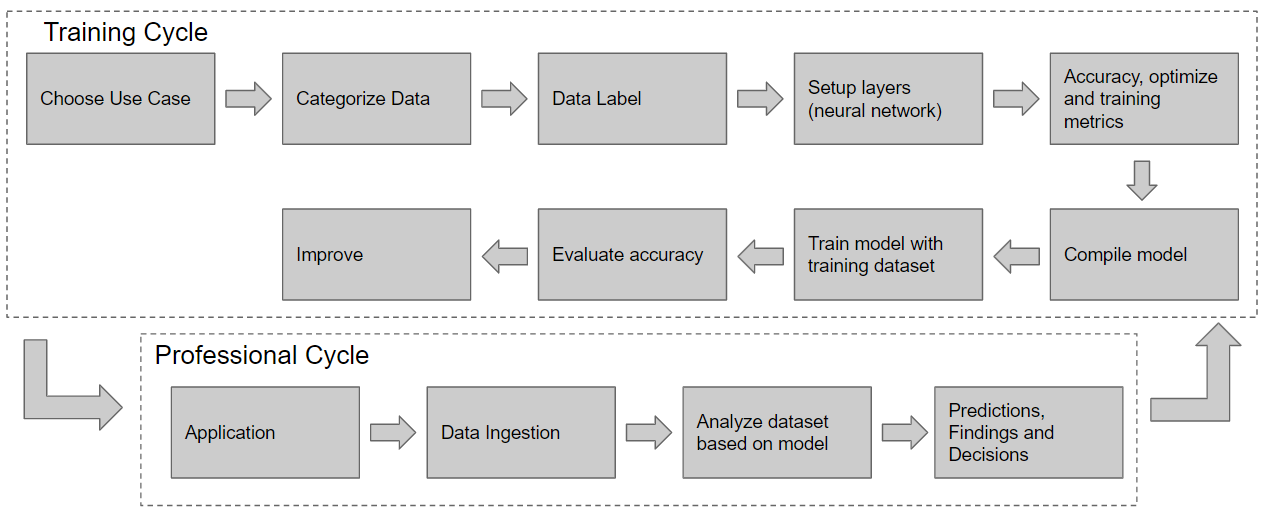
The goal is always to improve the accuracy of the model and it's ability to match an input with the best possible output. As such, models will likely be continually improved over time and there will be a continuous improvement cycle between the training and professional phases. However a trained model is expected to handle future problems or even unknowns. It is thought that a model would not be updated multiple times a day or every few days but should last weeks or maybe even months. Nevertheless there is a need to continue to learn just like humans.
Machine Learning Use Cases
Today there are a lot of use cases for machine learning, in the future there will be even more, as new patterns or frameworks become available and understood. Some of the more common use cases I consider valid for today are shown below.
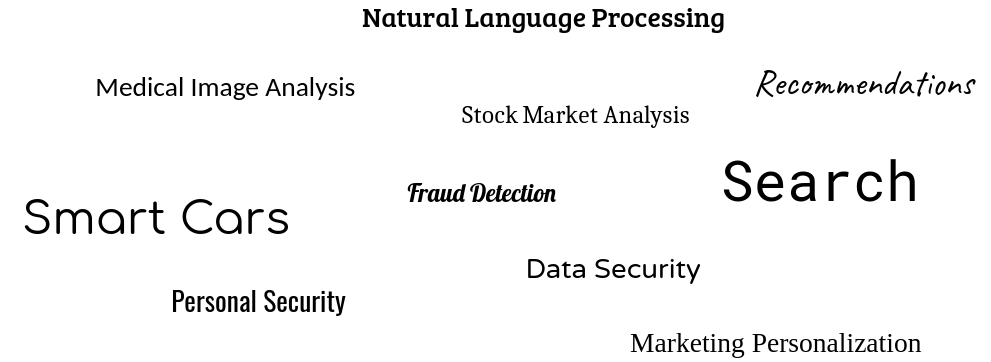
The important thing to remember is that machine learning will be replacing and greatly optimizing tasks not replacing humans themselves. The key as already stated about machine learning is to find the best output given an input, in order to make a decision. This probably also answers why search was one of the first use cases for machine learning. Regardless if we are talking about smart cars, analyzing medical imagery, stock market, providing personalized recommendations or even protecting security, the process or workflow is the same. The only thing that changes are the inputs/outputs, data labels or categorization, and sometimes the algorithms. As hinted creating new algorithms or defining new patters is really hard work and a really highly specialized field. However once the patterns or algorithms are known, they can be re-used and this is what everyone can leverage. For example if we take imagery, those patterns are well known and established. Depending on what you are doing you may only need to label your data and adapt what has already been done. If you are dealing with new types of imagery then it is still just a matter of adapting the frameworks that exist and tailoring it to your needs. An example of this is TenzorFlow (no affiliation to myself) which is a machine or deep learning framework that already has a lot of algorithms. TenzorFlow provides a abstraction and a workflow for handling the details of hitching input functions to output functions (neural connections). The whole point of machine learning is to analyze a very large data-set, train itself on all the patterns and connections to build a neural network and then based on a single input find the best possible output. Machine learning can do this better, faster and with more predictably than humans.
Machine Learning Requirements
Now that we have established a basic understanding for what machine learning is and where it can be used, let's get into some of the requirements. Below is a list of some of the more important things to take into consideration.
- Requires GPUs, not CPUs for best performance
- High memory requirements as trained models are loaded in memory
- Large data-set for training
- Trained models are very large, many, many GBs
- Complex, diverse software stack (python, modules, compilers, hardware drivers, integration layers)
- Multi-cloud being able to leverage software stacks and data-sets across cloud platforms, including the existing enterprise environments
If you add up all the requirements you end up with needing a very dynamic and flexible environment that cannot only scale but meet the challenges around diversity and integration. Machine learning needs data and as such it likely won't be some one-off, but rather integrated into the various sources of data in your enterprise environments. Containers and specifically a kubernetes based container platform is the only solution that can effectively meet the demands of machine learning workloads.
Containers provide process isolation while also providing an easy mechanism to package and transport such a complex software stacks across multi-cloud environments. A container platform enables ability to do many releases and fast rollouts of new capabilities without downtime. Models can be compiled and stored on persistent volumes so they don't reside in the containers themselves. Machine learning workloads can easily be isolated to compute nodes with GPUs and large amounts of memory, typically running on baremetal from other workloads that may be better suited for VMs or other hardware. Finally it is key that a container platform can run in the enterprise environment as well as public cloud. In addition must be open, allow necessary control and leverage the best capabilities in order to harness the true power machine learning offers.
Machine Learning Demo Application
As we have discussed there are two parts to machine learning: building a trained model and using it. Most people will be more interested with the latter as that is where you see business value. As such the demo focuses on using an already trained model. The demo application is a voice recognition system. It will take an audio file, decode audio into text and then translate that text to the language of our choice. The application is broken into three parts: frontend, backend and the trained model.
The front-end is written in nodejs while the back-end is python. Currently the container image has both but that could be broken apart with an additional API or middleware layer. The trained model is downloaded but stored on a persistent volume that is simply mounted in the container image. This allows us to make changes to front-end or back-end and quickly rebuild without having to download model again. It also allows for a separate CI/CD process for delivering the model. Trained models will also likely be continually improved in the goal to get better outputs and intelligence from the algorithms.
The back-end is using Mozilla Deepspeech to do the voice recognition. Mozilla DeepSpeech is a TenzorFlow implementation of Baidu's DeepSpeech architecture. We are using a basic trained English model (provided by DeepSpeech project) so accuracy is not nearly as good as it could if we trained the model to for example, with our voice, dialect or even other language characteristics. It is just intended for demo purposes not a real-world scenario. Once we have text we run the text through spell and accuracy correction and finally translate the text in to another language using Google Translate.
Deploy Machine Learning Demo Application
A Dockerfile is provided to build and deploy the application. Here we will deploy the application to OpenShift which is Red Hat's Enterprise Kubernetes platform. As I mentioned a container platform is critical and OpenShift provides an independent, open platform for machine learning workloads. If you don't have OpenShift I would recommend getting the community upstream version called OKD. If that isn't an option you can use plain-old boring Docker and do a docker build of the Dockerfile on your workstation.
Clone GitHub Repository
Clone the GitHub repository to your laptop or workstation.
$ git clone https://github.com/ktenzer/openshift-ml-demo.git
Login to OpenShift and create new project
A project in OpenShift is a namespace or workspace for applications.
Add Template into OpenShift
Templates in OpenShift provide pre-determined automation for how to build and deploy an application. The template we have provided takes care of building and deploying the demo application as well as configuring a persistent volume for storage and a URL or route.
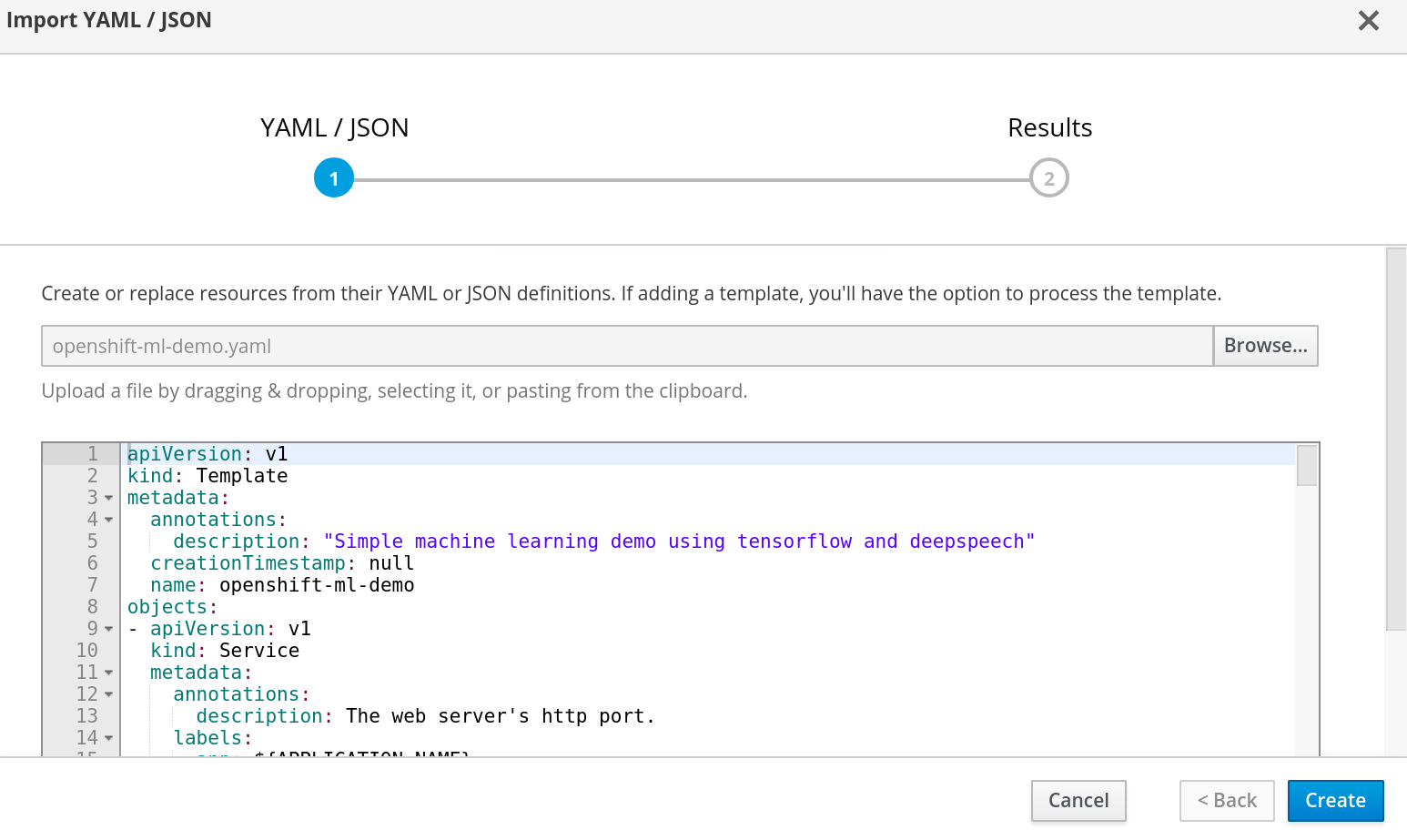
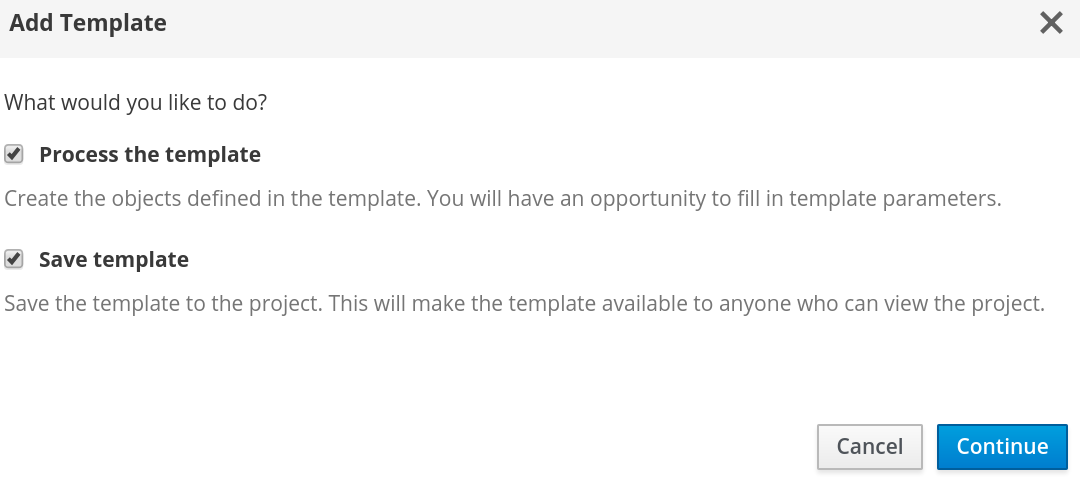
Next you can choose to process and save the template so it is available in the project or service catalog for later use. We will do both.
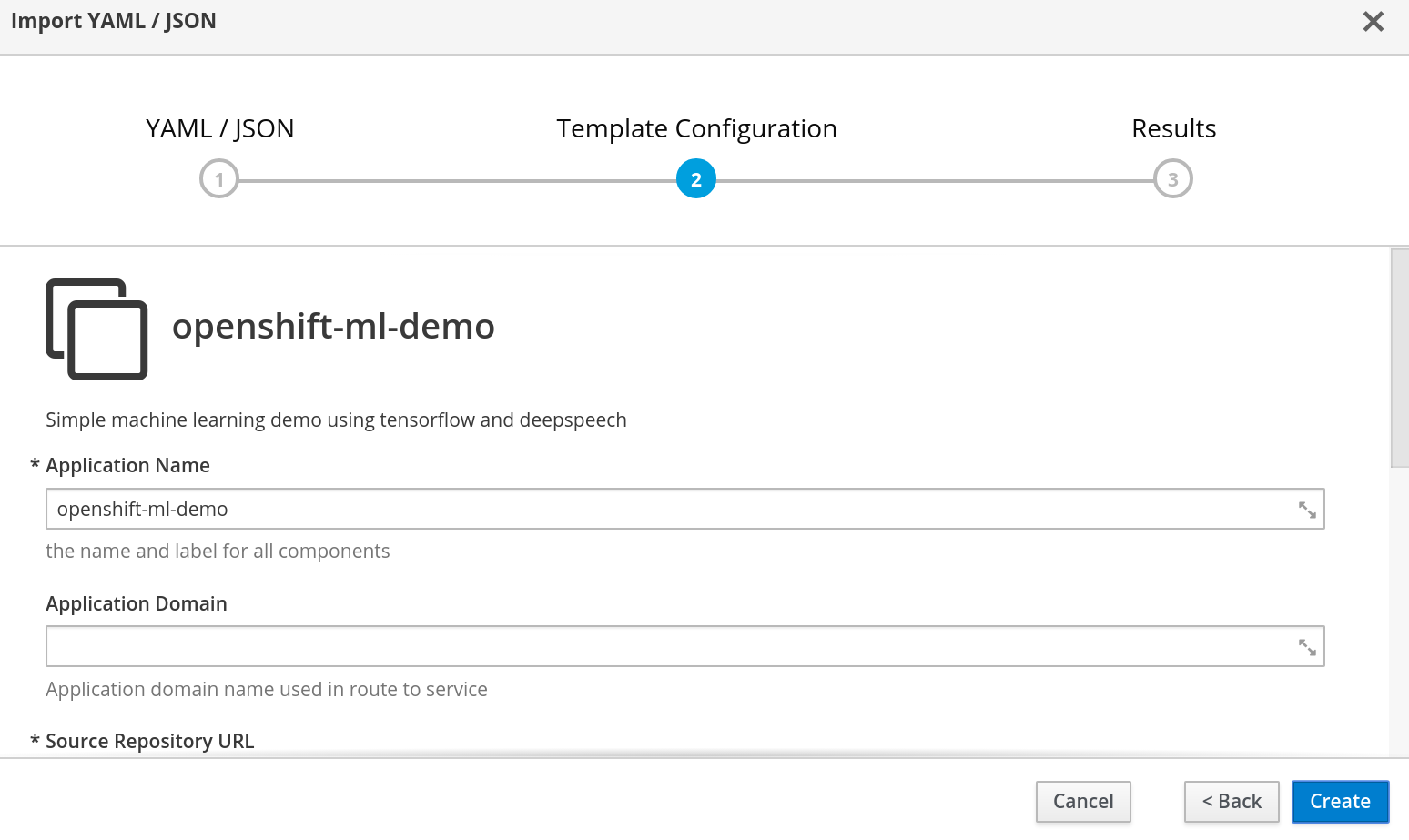
Update Template Parameters
Templates are parameterized by their creators. In this case we will leave the defaults.
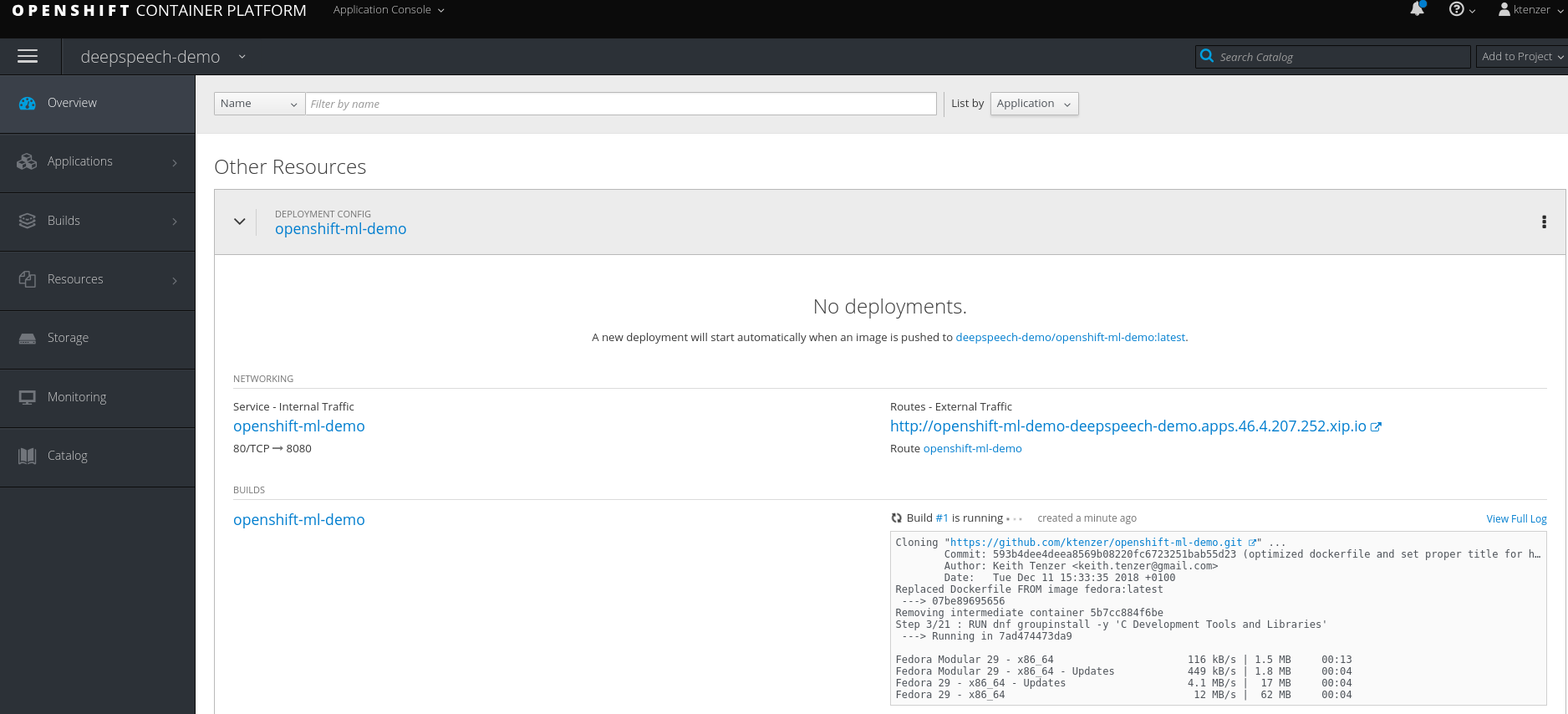
 Build Demo Application
Build Demo Application
After all the objects defined in the template are created, the build will start. In this step we will build a container image with the necessary software stack and python development environment to run the application.
Deploy Demo Application
The deployment is started after the build completes and the build artifact, which is a container image is saved in the OpenShift registry. The deployment schedules the application to run and the scheduler determines the most appropriate node. The images is then pulled from the OpenShift registry to the node. The pod will show a grey border while the image is being pulled to a node.
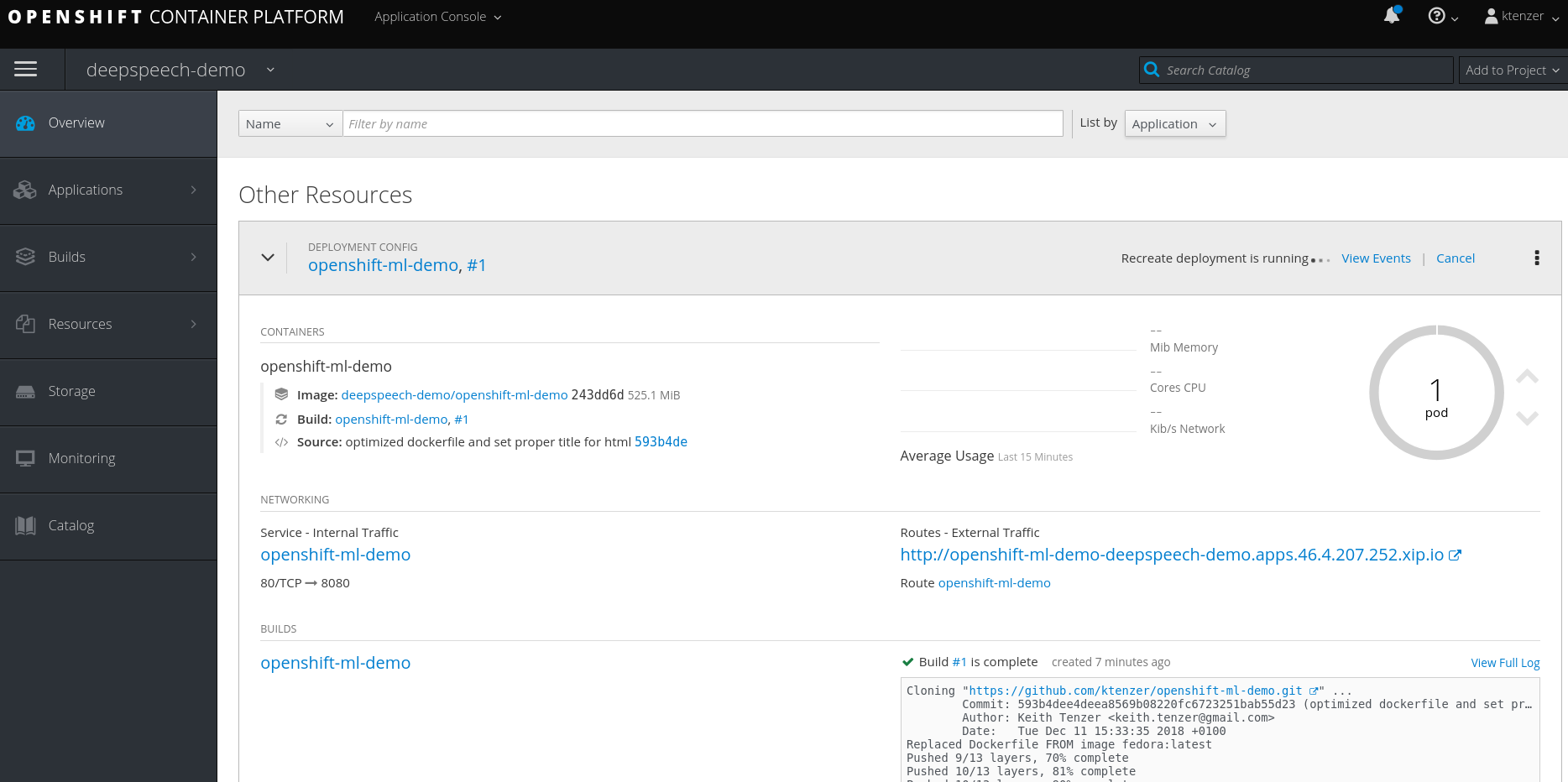
Once the image is pulled to the node it will be started on that node.
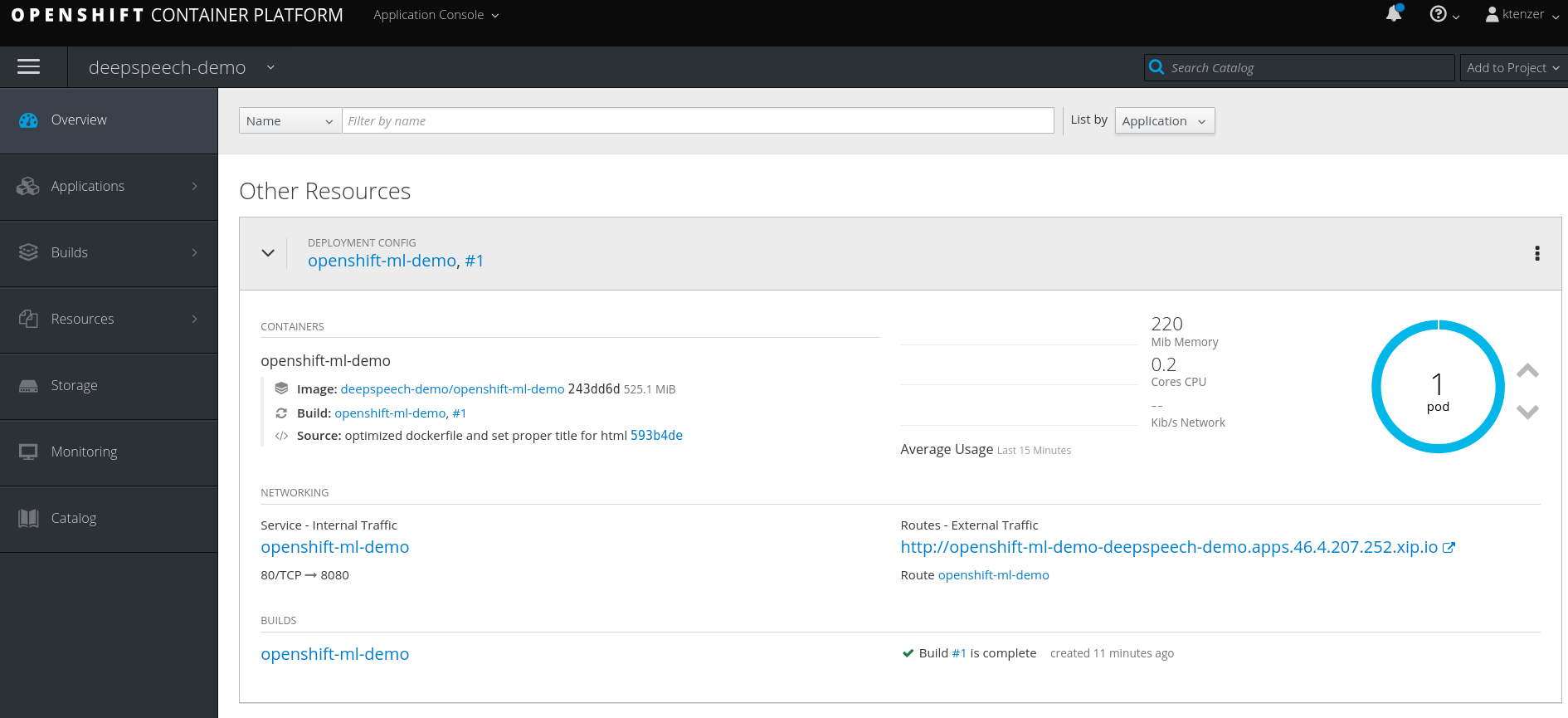
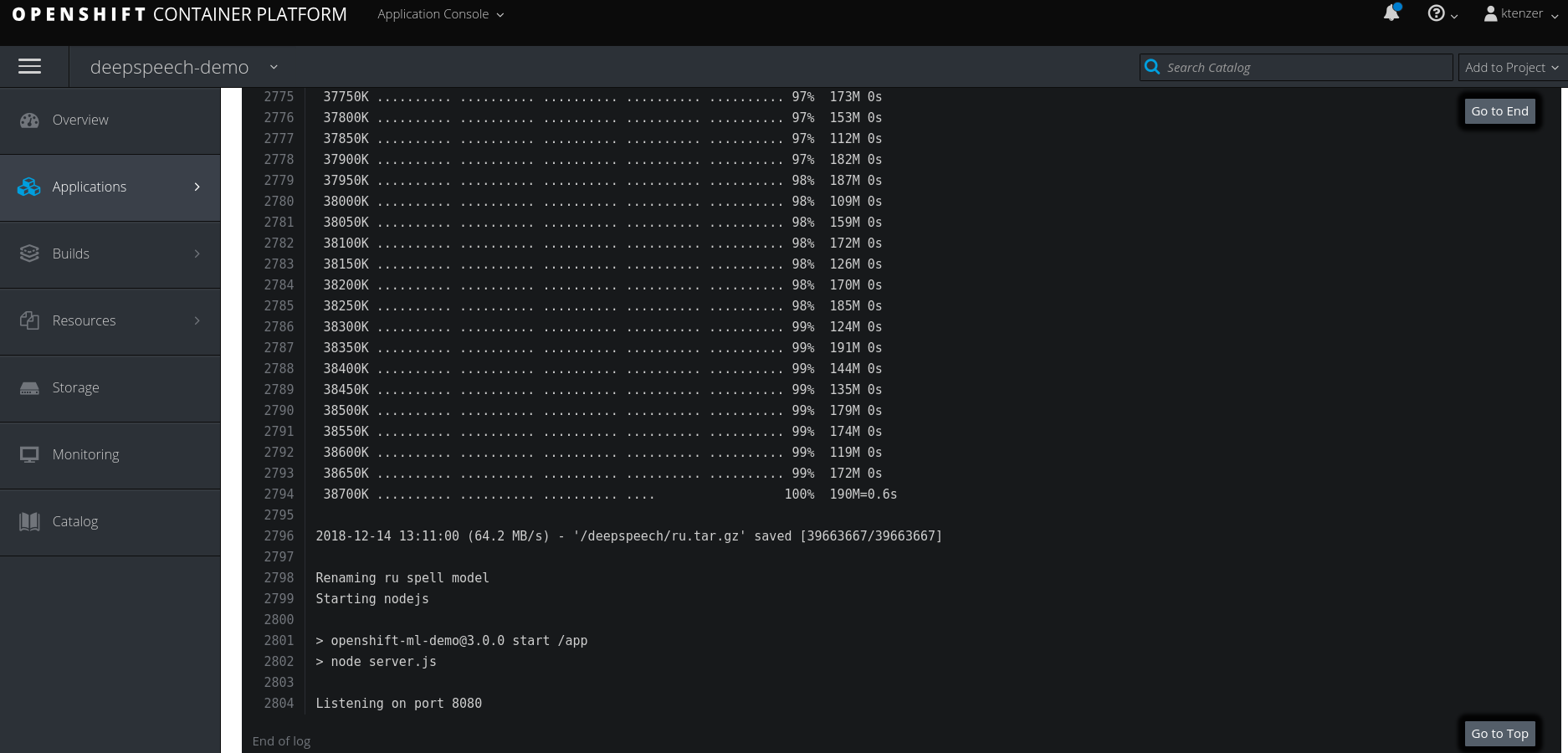
The first time the application starts it will download the trained model. You can follow this by looking in the pods and containers logs. Once the trained model is downloaded the nodejs server will be started and the application made available.
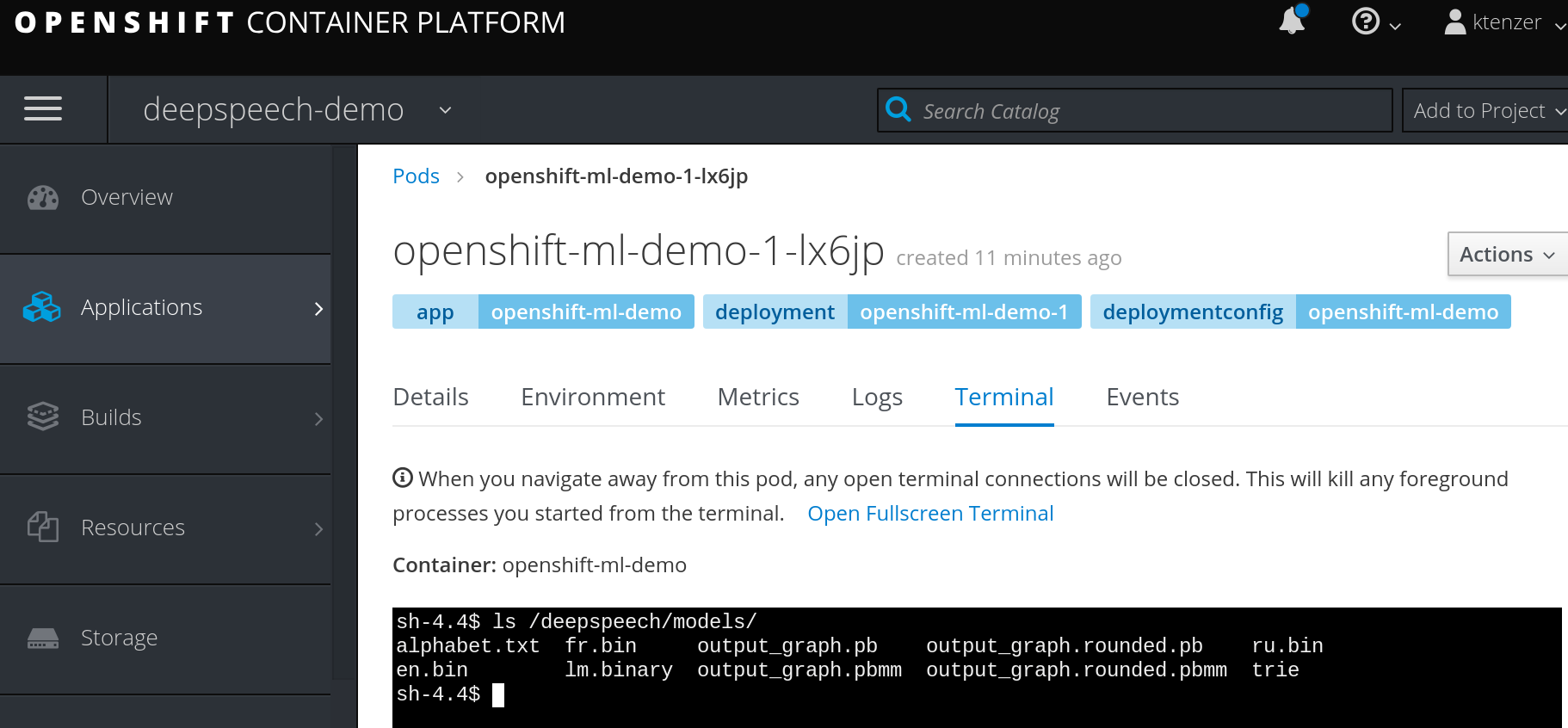
You can also access the pod and container and look at the downloaded models under the /deepspeech directory. This is of course a persistent model.
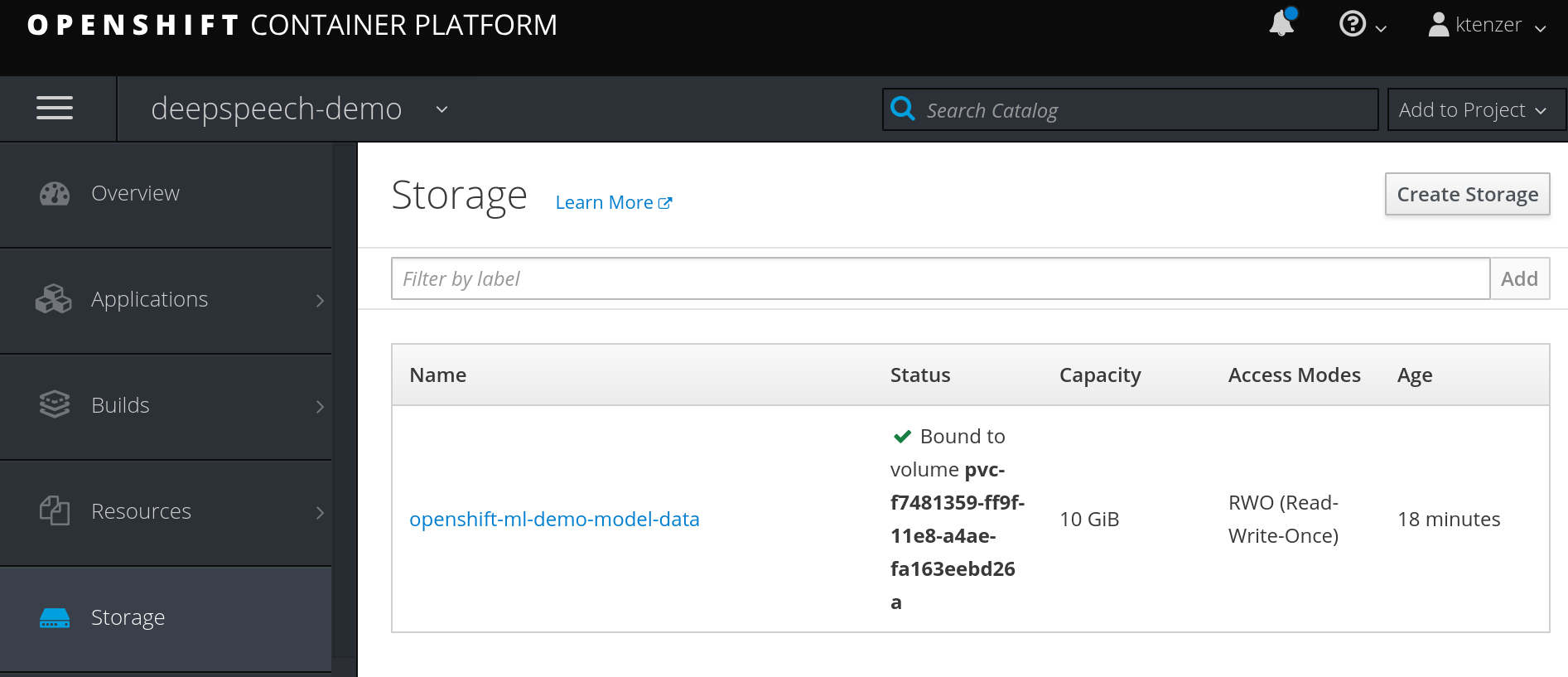
You can view the persistent volume used under storage in OpenShift.
Using Demo Application
To access application simply click the URL or route configured by the template.
Note: if it is still downloading the model (can take a while), application will not start or be available, so check the logs in the container and be patient the first time.

Click choose file to select an audio file. There is a demo.wav file in the GitHub repository provided for convenience. You can of course record your own audio just follow the requirements mentioned in the application.

Once you click submit the audio file is downloaded into the container image and run through the translate.py program which loads DeepSpeech and performs audio-to-text as well as translation to language chosen. Click the Results button to see the results.
Note: it may take a minute or two to see any results and the translation will be done step-by-step so you can see how DeepSpeech model is making decisions. You will notice it makes several mistakes that later are corrected. This really illustrates the power of machine learning and also the complexity of understanding voice in a compute program.

The last audio-to-text sentence and translation is displayed before end of translation message. As you can see it got everything almost perfect.

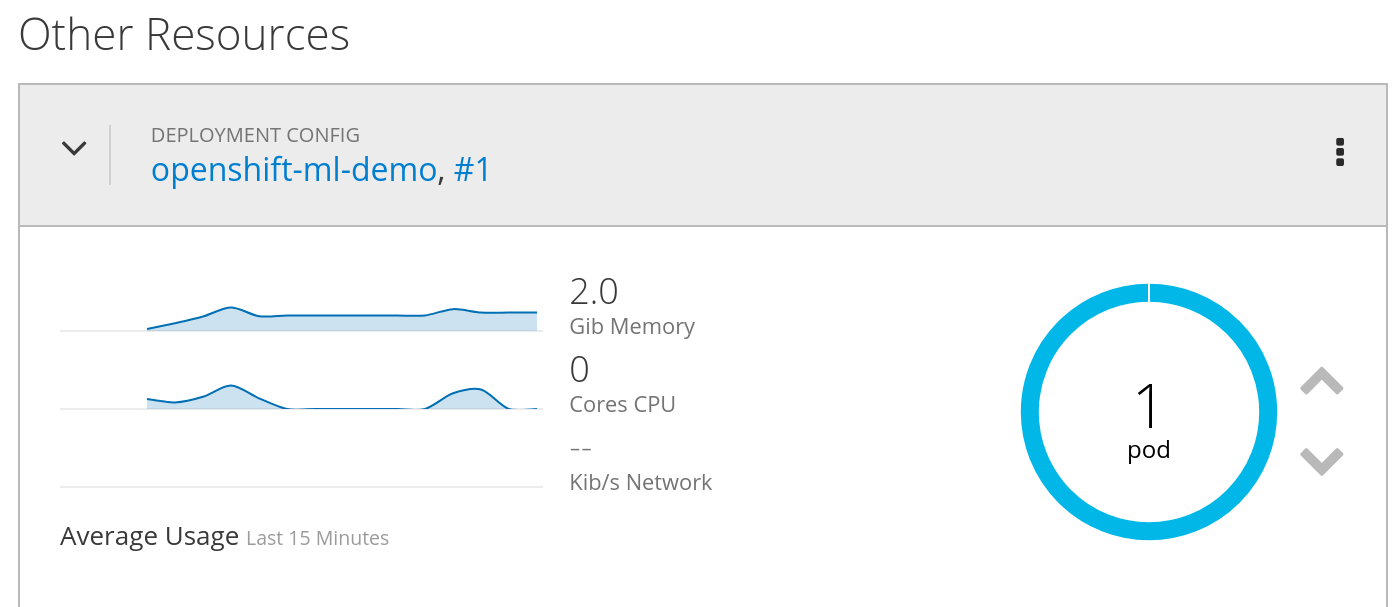
Once the model runs you will notice quite a bit of memory and some CPU usage. The model is loaded into memory so you can imagine the usage for a much larger model, this one is only around 2GB. CPU/GPU usage will vary depending on size of the audio file and data-set.
Video
Below is a video recording of the demo.
[wpvideo lLhyPenM]
Summary
In this article we gained a broader understanding for machine learning. By exploring use cases we saw just how wide reaching machine learning has become today and garnered new appreciation for it's potential in the future. Looking into the requirements of machine learning workloads we were able to see the value of containers and a container platform. I am convinced given the diversity of the software stack, the integration required into multiple clouds as well as data-sets and the flexibility needed that a container platform, is the only option we should be considering for machine learning workloads. Finally a demo was provided to put more context around machine learning, show that it is actually simple to utilize and allow us to understand better what running machine learning workloads actually means.
Happy Machine Learning!
(c) 2018 Keith Tenzer